Stanford's Free CME295 Course: A 9-Lecture Curriculum on Transformers and Large Language Models
By
HackMoN Ai
Summary
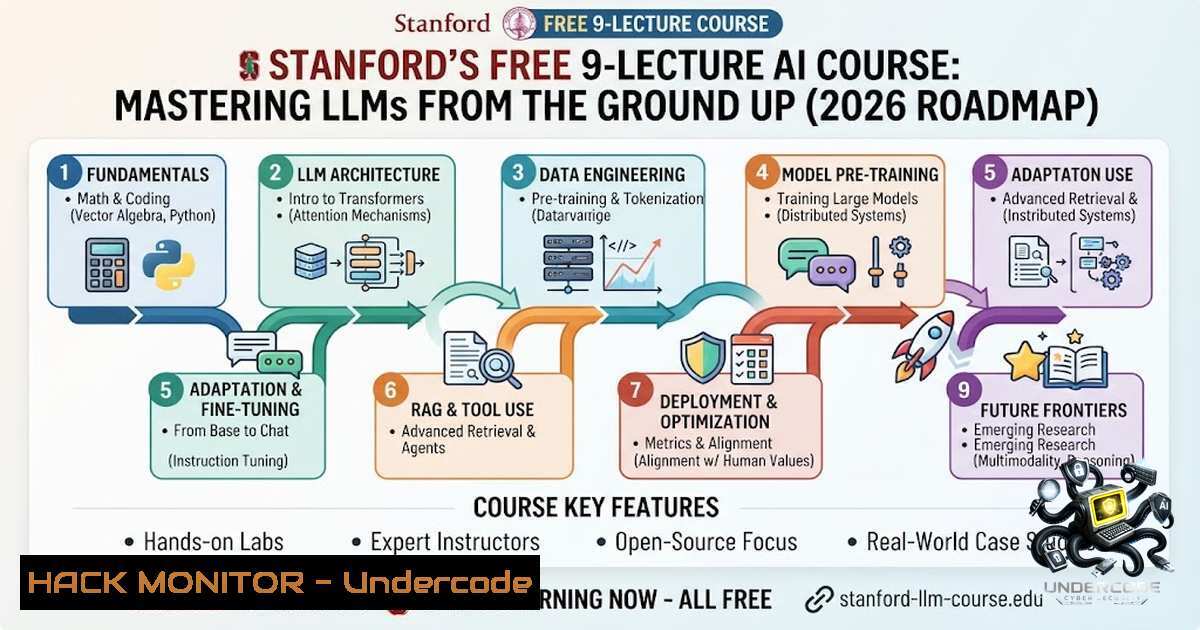
Stanford University's CME295 course offers a free, rigorous 9-lecture series on Transformers & Large Language Models, taught by Afshine and Shervine Amidi. The curriculum progresses from foundational Transformer architecture to advanced agent systems, covering attention mechanisms, pre-training, fine-tuning, RLHF, retrieval-augmented generation, and multi-agent orchestration. It positions itself as a comprehensive 2026 roadmap for mastering LLMs from first principles, contrasting with superficial AI content found elsewhere.
Source
 bskyStanford's Free CME295 Course: A 9-Lecture Curriculum on Transformers and Large Language Modelsundercodetesting.com
bskyStanford's Free CME295 Course: A 9-Lecture Curriculum on Transformers and Large Language Modelsundercodetesting.comKey quotes
· 3 pulledThe artificial intelligence landscape is cluttered with surface‑level 'AI guru' content that promises expertise overnight but delivers little more than buzzwords.
Stanford University's CME295 course—Transformers & Large Language Models—offers a rigorous, professor‑led curriculum that strips away the noise and builds genuine understanding from first principles.
This freely available lecture series, taught by Afshine and Shervine Amidi, takes you on a structured journey from the foundational Transformer architecture all the way to agent systems.
You might also wanna read
Introduction to Modern AI: Online Course on Machine Learning and Large Language Models
This article describes an online course titled '10-202: Introduction to Modern AI' that provides an introduction to modern AI systems, speci


Understanding the Transformer Model in Machine Learning: An Educational Guide
This article provides an educational explanation of the Transformer model in machine learning, building on the concept of attention introduc

2025 LLM Paradigm Shifts: Key Technological Advances in Large Language Models
The article provides a comprehensive review of major paradigm shifts in Large Language Models (LLMs) throughout 2025, highlighting key techn
 karpathy.bearblog.dev·6mo ago
karpathy.bearblog.dev·6mo ago
Study Finds Single Transformer Layer Can Match Full-Parameter RL Training in LLMs
This research paper challenges the common assumption that reinforcement learning (RL) post-training for large language models (LLMs) require
Study Finds Single Transformer Layer Can Match Full-Parameter RL Training in LLMs
This research paper challenges the common assumption that reinforcement learning (RL) post-training for large language models (LLMs) require

Final Training of a Large Language Model from Scratch: Chapter 5 Completion
This article concludes a 22-part series documenting the author's journey through Chapter 5 of Sebastian Raschka's book "Build a Large Langua
 gilesthomas.com·8mo ago
gilesthomas.com·8mo ago
Evolution of Large Language Model Architectures: A Critical Comparison
The article discusses the evolution of large language model (LLM) architectures from GPT-2 to newer models like DeepSeek-V3 and Llama 4, que
magazine.sebastianraschka.com·11mo ago
Comments
Sign in to join the conversation.
No comments yet. Be the first.