Understanding Scaling Laws in Deep Learning: A Framework for Optimal Compute Allocation
By
Lilian Weng
Summary
This article provides an in-depth analysis of scaling laws in deep learning — the empirical finding that training loss decreases predictably as model size, dataset size, and compute are scaled up, following a power-law relationship. It explores how these laws serve as a framework for optimally allocating compute resources between model size and data, and discusses their practical value in guiding training workflows and resource allocation decisions in AI research.
Source
 bskyUnderstanding Scaling Laws in Deep Learning: A Framework for Optimal Compute Allocationlilianweng.github.io
bskyUnderstanding Scaling Laws in Deep Learning: A Framework for Optimal Compute Allocationlilianweng.github.ioKey quotes
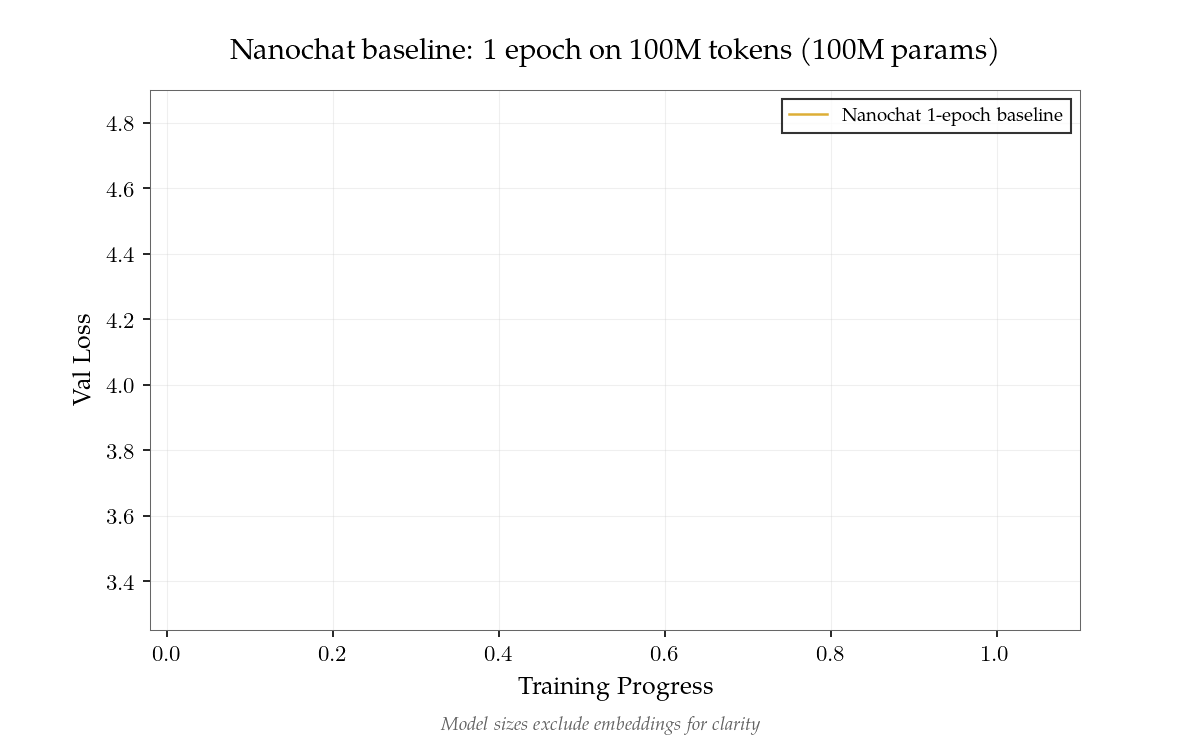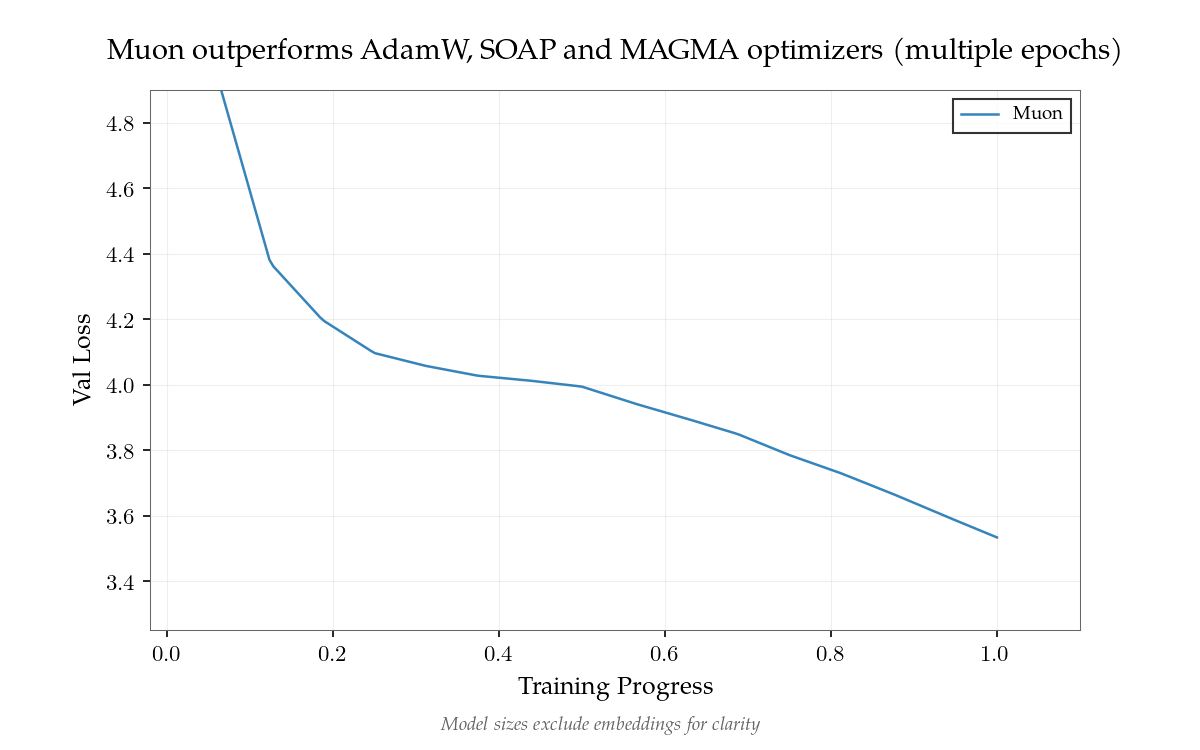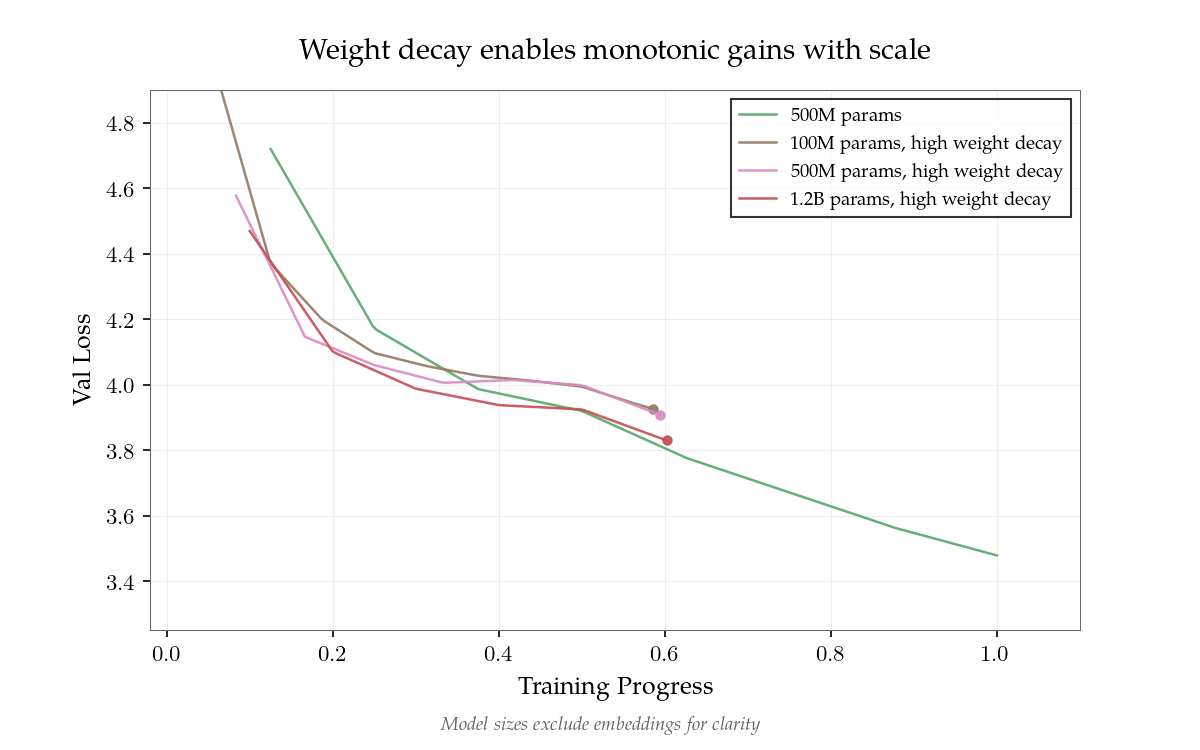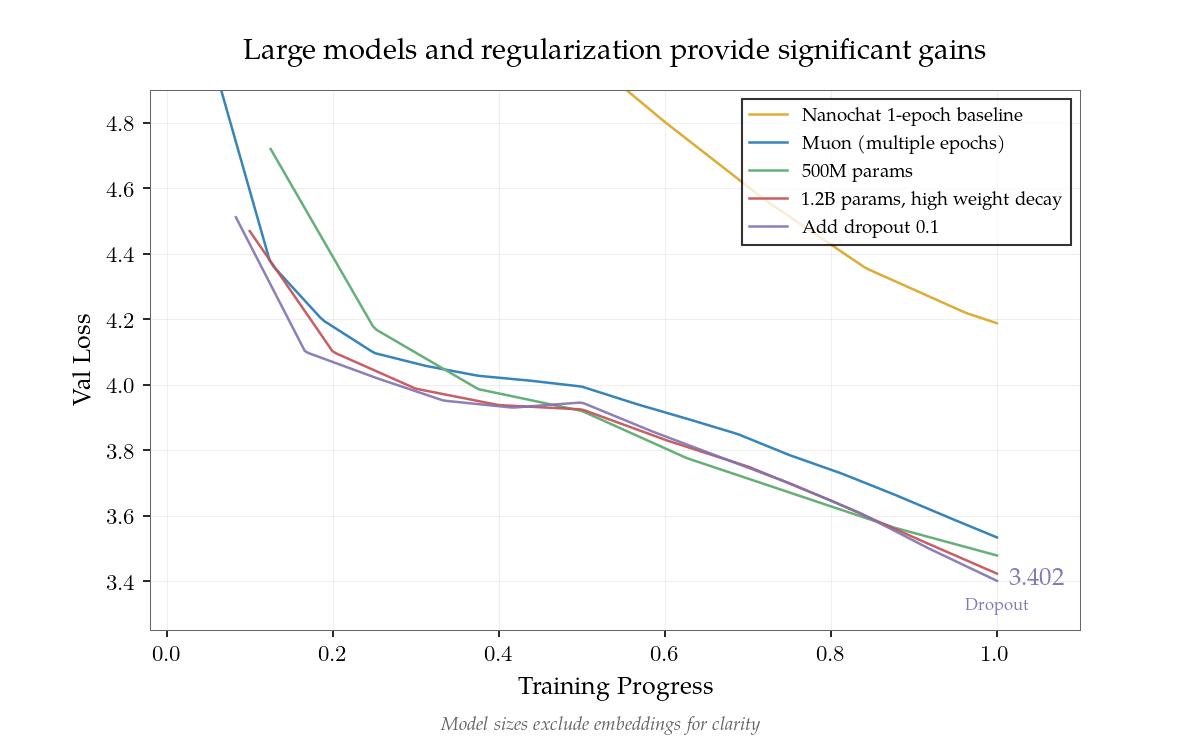
· 4 pulledScaling laws are one of the most critical empirical findings in deep learning.
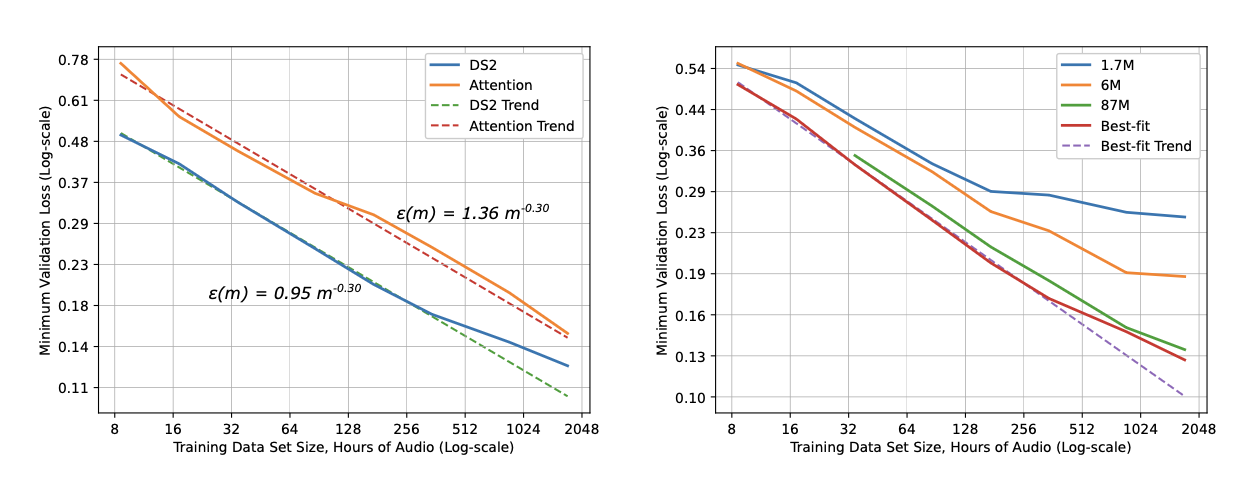
The observation is simple in form: the training loss L decreases predictably as we scale up model size N, dataset size D, and compute C, following a power-law curve.
We can view scaling laws as a framework for describing the relationship between compute, loss, model size and data; at its core, it is about how to allocate precious compute optimally between N and D.
This predictability makes scaling laws highly valuable in practice.
You might also wanna read


Scaling Laws Limit Reliability of Large Language Models, Study Finds
This research paper demonstrates that the scaling laws governing large language models (LLMs) fundamentally limit their ability to improve p
Data Scarcity as the Emerging Bottleneck in AI Scaling and Intelligence Development
The article discusses the asymmetry between compute and data growth in AI development, arguing that while compute capacity grows rapidly, da

Parameters vs. Computation: Understanding Deep Learning Model Efficiency Metrics
This article explores the relationship between model parameters and computation in deep learning. It argues that while model size (number of
 parl.ai·2mo ago
parl.ai·2mo ago
A Practical Guide to Scaling Language Models: From Single Accelerators to Thousands
This article/book excerpt demystifies the science of scaling language models, explaining how TPUs and GPUs work, how they communicate, how L
 jax-ml.github.io·8h ago
jax-ml.github.io·8h agoA Practical Guide to Scaling Language Models: From Single Accelerators to Thousands
This article/book excerpt demystifies the science of scaling language models, explaining how TPUs and GPUs work, how they communicate, how L
jax-ml.github.io·8h ago
Emerging Scientific Theory of Deep Learning: The Case for "Learning Mechanics"
This academic paper argues that a scientific theory of deep learning is emerging, which the authors call "learning mechanics." They identify

Rethinking Overparameterization: Why the Lottery Ticket Analogy Falls Short
This article critiques the popular "lottery ticket" analogy used to explain the success of overparameterized neural networks. The authors ar
 infoscience.epfl.ch·1d ago
infoscience.epfl.ch·1d ago
Comments
Sign in to join the conversation.
No comments yet. Be the first.