Parameters vs. Computation: Understanding Deep Learning Model Efficiency Metrics
When we talk about the power of a deep learning model, often the only metric we pay attention to is its size, which is measured by the number parameters in that model. However, the amount of…
Read the full articleYou might also wanna read

Understanding Scaling Laws in Deep Learning: A Framework for Optimal Compute Allocation
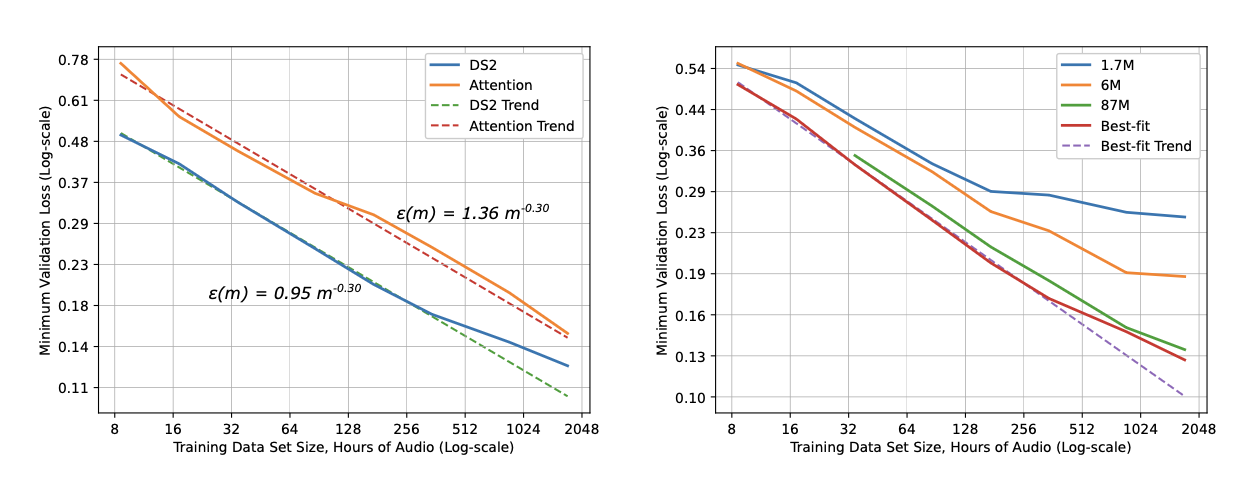
Scaling laws are one of the most critical empirical findings in deep learning. The observation is simple in form: the training loss $L$ decr
 lilianweng.github.io·20d ago
lilianweng.github.io·20d agoUnderstanding Scaling Laws in Deep Learning: A Framework for Optimal Compute Allocation
Scaling laws are one of the most critical empirical findings in deep learning. The observation is simple in form: the training loss $L$ decr
lilianweng.github.io·20d agoUnderstanding Scaling Laws in Deep Learning: A Framework for Optimal Compute Allocation
Scaling laws are one of the most critical empirical findings in deep learning. The observation is simple in form: the training loss $L$ decr
lilianweng.github.io·20d agoTest-Time Compute Is Reshaping AI Inference Architecture Beyond Scaling Laws
For years, AI progress relied on scaling models with more data and parameters, but researchers and engineers are now focused on a different

Theoretical Analysis Reveals Why Linear RNNs Are More Parallelizable Than Nonlinear RNNs
The community is increasingly exploring linear RNNs (LRNNs) as language models, motivated by their expressive power and parallelizability. W

Wider Neural Networks with Fewer Parameters Improve Performance by Reducing Feature Interference
This work demonstrates how increasing the number of neurons in a network without increasing its total number of non-zero parameters improves

LLM Inference Benchmarking - Measure What Matters
Production-grade LLM inference is a complex systems challenge, requiring deep co-designs - from hardware primitives (FLOPs, memory bandwidth

Looped Transformers Require Stronger Residual Scaling: 1/N Outperforms 1/√N for Weight-Tied Architectures
Looped (weight-tied) Transformers apply a shared residual block $N$ times ($h \leftarrow h + \varepsilon\,f(h)$, same $f$ at each step), inc
Comments
Sign in to join the conversation.
No comments yet. Be the first.