R2 SQL - R2 SQL now supports approximate aggregation functions
4mo ago
Source
CloudflareR2 SQL - R2 SQL now supports approximate aggregation functionscloudflare.comR2 SQL now supports five approximate aggregation functions for fast analysis of large datasets. These functions trade minor precision for improved performance on high-cardinality data. New functions APPROX_PERCENTILE_CONT(column, percentile) — Returns the approximate value at a given percentile (0.0 to 1.0). Works on integer and decimal columns. APPROX_PERCENTILE_CONT_WITH_WEIGHT(column, weight, percentile) — Weighted percentile calculation where each row contributes proportionally to its weight column value. APPROX_MEDIAN(column) — Returns the approximate median. Equivalent to APPROX_PERCENTILE_CONT(column, 0.5) . APPROX_DISTINCT(column) — Returns the approximate number of distinct values. Works on any column type. APPROX_TOP_K(column, k) — Returns the k most frequent values with their counts as a JSON array. All functions support WHERE filters. All except APPROX_TOP_K support GROUP BY . Examples -- Percentile analysis on revenue data SELECT approx_percentile_cont (total_amount, 0 . 25 ), approx_percentile_cont (total_amount, 0 . 5 ), approx_percentile_cont (total_amount, 0 . 75 ) FROM my_namespace.sales_data -- Median per department SELECT department, approx_median(total_amount) FROM my_namespace.sales_data GROUP BY department -- Approximate distinct customers by region SELECT region, approx_distinct(customer_id) FROM my_namespace.sales_data GROUP BY region -- Top 5 most frequent departments SELECT approx_top_k(department, 5 ) FROM my_namespace.sales_data -- Combine approximate and standard aggregations SELECT COUNT ( * ), AVG (total_amount), approx_percentile_cont (total_amount, 0 . 5 ), approx_distinct(customer_id) FROM my_namespace.sales_data WHERE region = 'North' For the full syntax and additional examples, refer to the SQL reference .
You might also wanna read
Version 18.2
Microsoft·1mo ago


Technical Discussion: Distributed SQL Engine Requirements for Ultra-Wide Tables in ML and Multi-Omics Data
A technical discussion about the limitations of current SQL databases and data processing systems when handling ultra-wide tables with thous
 news.ycombinator.com·5mo ago
news.ycombinator.com·5mo ago
How rqlite Addresses the CAP Theorem in Distributed Databases
The article explores how rqlite, a lightweight, open-source distributed relational database written in Go and using SQLite, navigates the CA
 philipotoole.com·11mo ago
philipotoole.com·11mo ago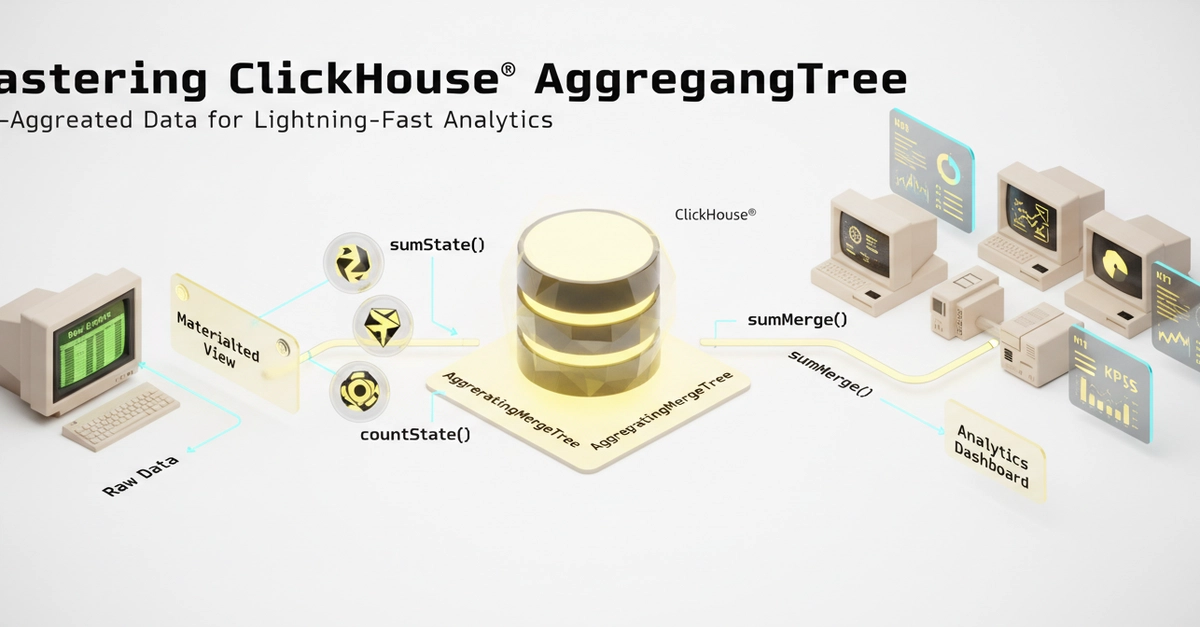
ClickHouse AggregatingMergeTree: Accelerating Analytics with Pre-Aggregated Data
This article explains ClickHouse's AggregatingMergeTree engine, which pre-aggregates data to speed up analytical queries on large datasets.
 dev.to·1d ago
dev.to·1d ago
Reevaluating Sixth Normal Form (6NF) in Relational Database Modeling
The article explores the historical reverence for Sixth Normal Form (6NF) in relational database modeling, questioning its perceived impract

SQLite Query Optimization: Using Uncorrelated Subqueries to Skip Correlated Subqueries for Performance Gains
The article describes a SQLite query optimization technique where an uncorrelated scalar subquery is used to skip expensive correlated subqu
 emschwartz.me·6mo ago
emschwartz.me·6mo ago
Comments
Sign in to join the conversation.
No comments yet. Be the first.