University of Manchester expands research computing with NVIDIA H200 nodes and 230 TB storage
By
Author: Martin Wolstencroft
Summary
The Research IT Platforms team at the University of Manchester, in partnership with Alces, expanded the Computational Shared Facility (CSF) in late 2025 by adding four 8-way NVIDIA H200 HGX compute nodes and 230 TB of high-performance storage. The upgrade was completed without disrupting existing CSF systems, enabling uninterrupted research work. The H200 GPUs were chosen for their impressive performance capabilities to accelerate research computing.
Source

 bskyUniversity of Manchester expands research computing with NVIDIA H200 nodes and 230 TB storageresearch-it.manchester.ac.uk
bskyUniversity of Manchester expands research computing with NVIDIA H200 nodes and 230 TB storageresearch-it.manchester.ac.ukKey quotes
· 2 pulledThe whole process was completed without disruption to other CSF systems, ensuring that researchers using the CSF could continue their work uninterrupted.
The H200 is an impressive
You might also wanna read

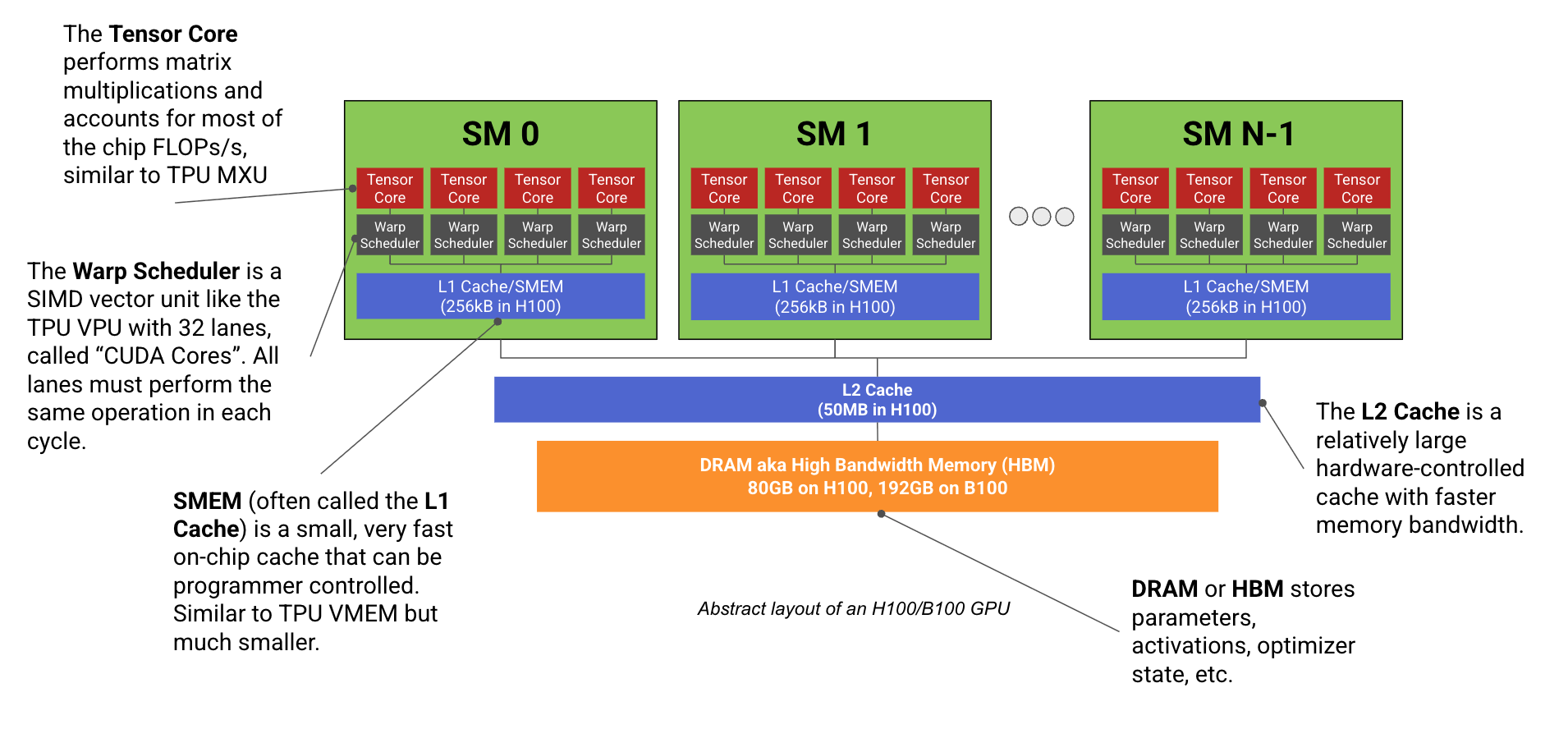
Understanding Modern GPU Architecture for Machine Learning: H100 and B200 Technical Analysis
This article provides a technical deep dive into modern GPU architecture, specifically focusing on NVIDIA GPUs like H100 and B200 used for m
 jax-ml.github.io·10mo ago
jax-ml.github.io·10mo ago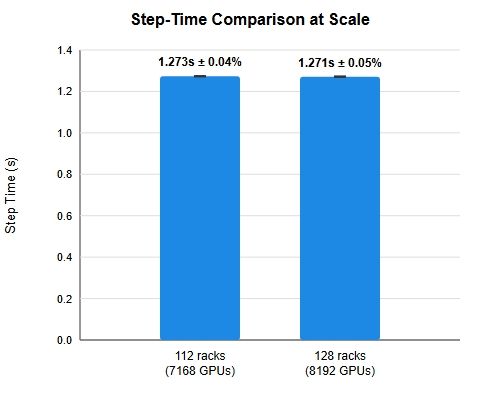
Azure achieves record MLPerf training time for Llama 405B using 8,192-GPU cluster
Azure achieved the most performant MLPerf Training v6.0 result for Llama 3.1 405B, training the model in just over seven minutes using a mas
 techcommunity.microsoft.com·12d ago
techcommunity.microsoft.com·12d ago
Deploying AMD's MI300X: Challenges and Trade-offs in the AI Compute Shortage
Doubleword is building an inference cloud and evaluating AMD's MI300X GPU as an alternative to NVIDIA's H100 amid a severe compute shortage.
 fergusfinn.com·26d ago
fergusfinn.com·26d ago
Nvidia-backed Starcloud Trains First AI Model in Space Using Satellite with H100 GPU
Nvidia-backed startup Starcloud successfully trained an AI model in space for the first time using a satellite equipped with an Nvidia H100
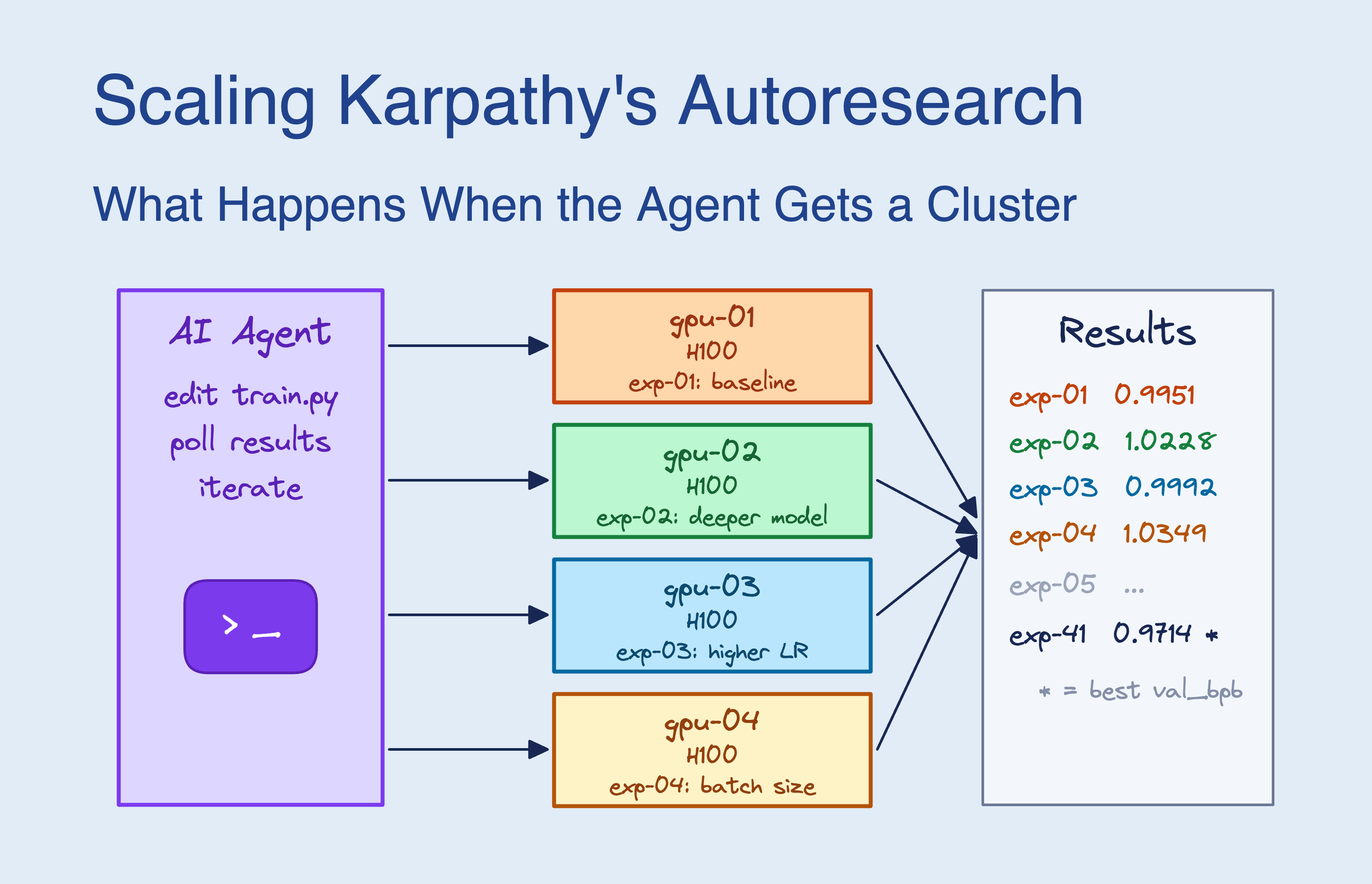
Scaling Karpathy's Autoresearch: Parallel GPU Processing Enables New AI Experimentation Strategies
The article describes an experiment where researchers scaled Andrej Karpathy's autoresearch system by giving it access to 16 GPUs on a Kuber
 blog.skypilot.co·3mo ago
blog.skypilot.co·3mo ago
Analysis of Google's Tensor Processing Unit (TPU) and Its Role in AI Acceleration
The article provides an in-depth analysis of Google's Tensor Processing Unit (TPU), positioning it as the original existence proof in the AI
 considerthebulldog.com·6mo ago
considerthebulldog.com·6mo ago
Comments
Sign in to join the conversation.
No comments yet. Be the first.