NanoGPT Slowrun Achieves 10x Data Efficiency Breakthrough in Language Model Training
By
sdpmas
An everything bagel for the brain. Substantive, layered, well-seasoned.
Summary
Researchers have achieved 10x data efficiency with NanoGPT Slowrun, where an ensemble of 1.8B parameter models (totaling 18B parameters) trained on just 100M tokens matches the performance that would normally require 1B tokens with standard language model baselines. This breakthrough addresses the growing concern that as compute power increases faster than available data, artificial intelligence development will eventually be bottlenecked by data scarcity rather than computational resources. The improved data efficiency enables scaling model performance primarily through increased compute rather than requiring proportional increases in both compute and data.
Key quotes
· 5 pulledWe've achieved 10x data efficiency with NanoGPT Slowrun within a few weeks.
An ensemble of 1.8B parameter models (18B total params) trained on 100M tokens matches what would normally require 1B tokens with a standard LM baseline.
Data efficiency matters because compute grows much faster than data.
Since our current scaling laws require proportional increases in both, intelligence will eventually be bottlenecked by data, not compute.
This data efficiency result allows us to improve model performance by scaling with compute rather than with data.
You might also wanna read


What pretraining on unlabeled text teaches large language models about language structure
Pretraining on unlabeled text teaches large language models to model the statistical structure of language by optimizing next-token predicti
 sebastianraschka.com·1d ago
sebastianraschka.com·1d ago
Demis Hassabis: AI will enable PhD students to match whole lab productivity
Demis Hassabis, Nobel laureate and Google DeepMind co-founder, stated at the 2026 Nobel Prize Dialogue in London that AI will soon enable a
 researchprofessionalnews.com·4d ago
researchprofessionalnews.com·4d ago
Decoding AI's Internal Language: How Sparse Autoencoders Help Interpret Neural Activations
This article discusses how AI models like Claude process language through numerical activations, similar to neural activity in the human bra
 anthropic.com·24d ago
anthropic.com·24d ago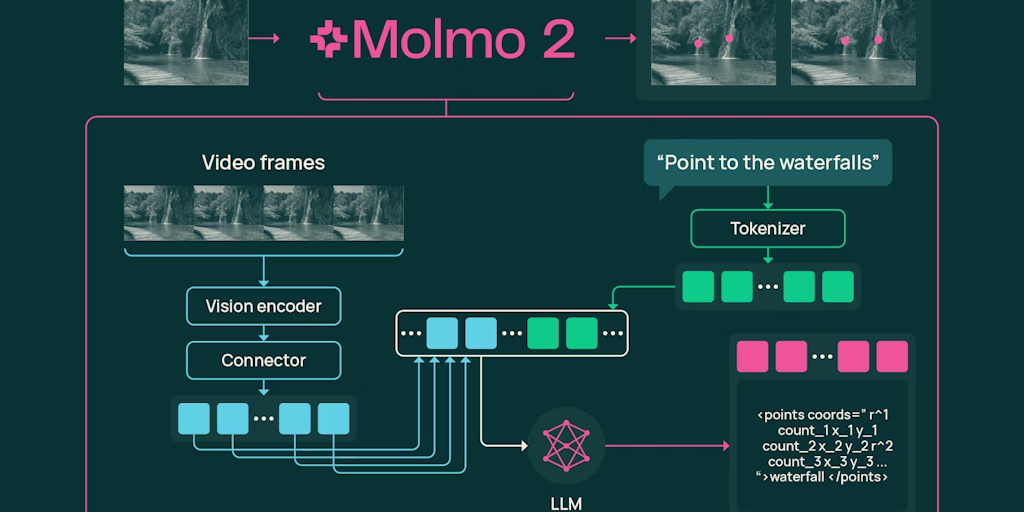
Allen Institute Releases Objaverse: 800K+ Annotated 3D Objects Dataset
The Allen Institute of Artificial Intelligence has released Objaverse, a massive dataset containing over 800,000 annotated 3D objects. This
 Product Hunt·26d ago
Product Hunt·26d agoHow Large Language Models Work: A Visual Deep Dive into Training Data Collection
This article provides a visual deep dive into how Large Language Models (LLMs) work, starting with the data collection process. It explains
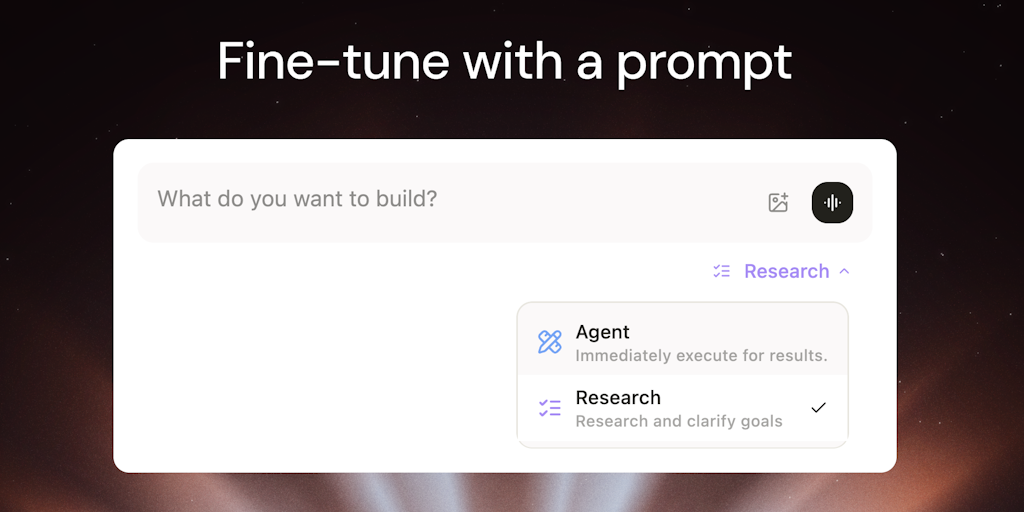
Pioneer Platform Enables Quick Fine-Tuning of Small Language Models with Plain English Prompts
Pioneer is a platform that enables users to fine-tune small language models (SLMs) in minutes using plain English prompts. The system handle
Product Hunt·1mo ago