Appears on

Articles2
NanoGPT Slowrun Achieves 10x Data Efficiency Breakthrough in Language Model Training
Researchers have achieved 10x data efficiency with NanoGPT Slowrun, where an ensemble of 1.8B parameter models (totaling 18B parameters) trained on just 100M tokens matches the performance that would normally require 1B tokens with standard language model baselines. This breakthrough addresses the growing concern that as compute power increases faster than a
News
qlabs.sh2mo ago

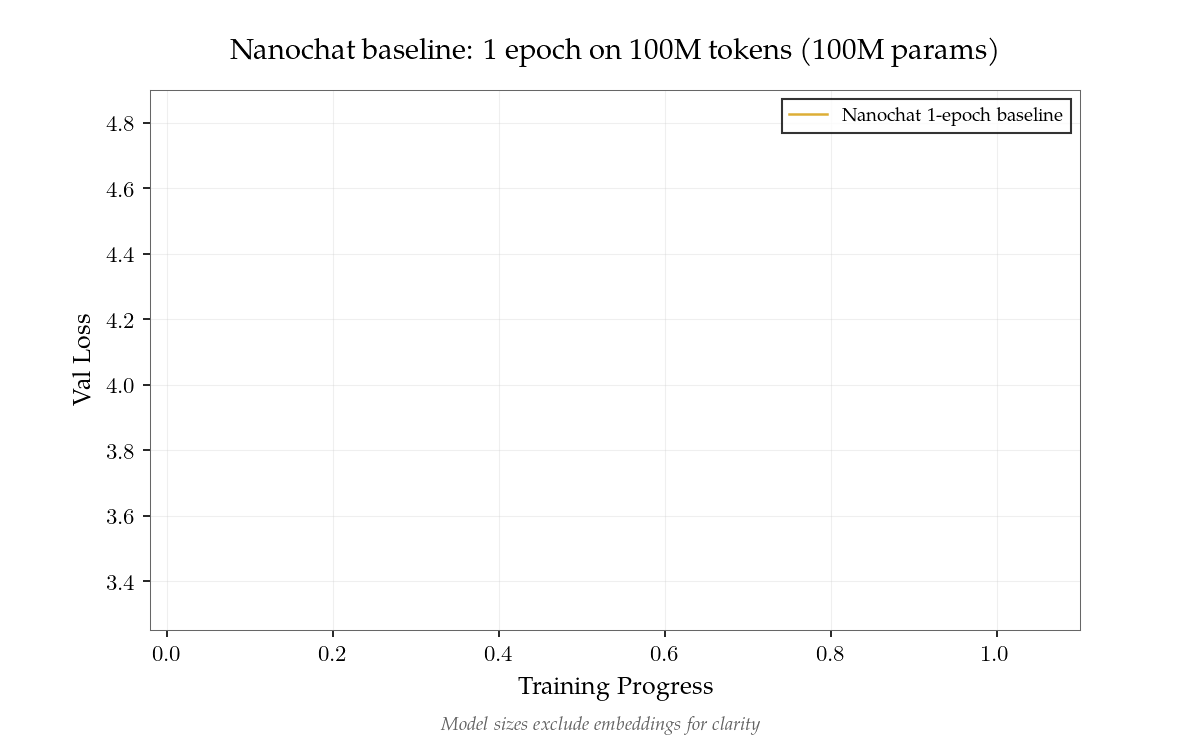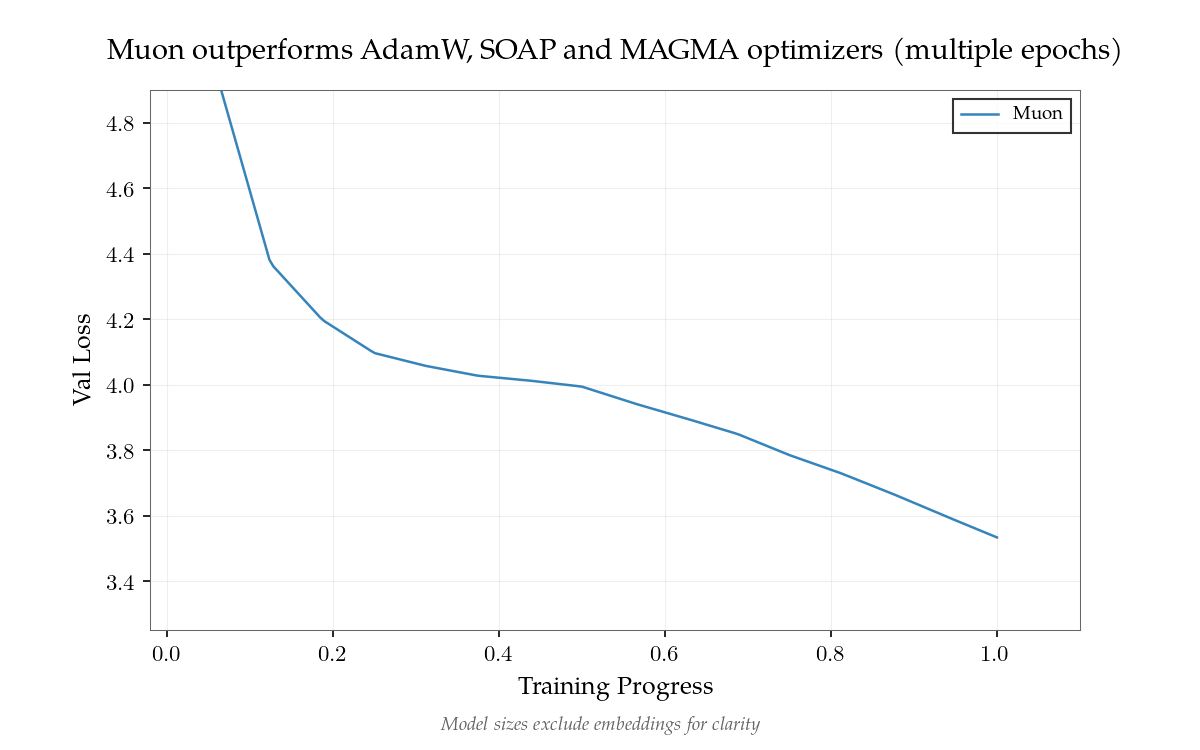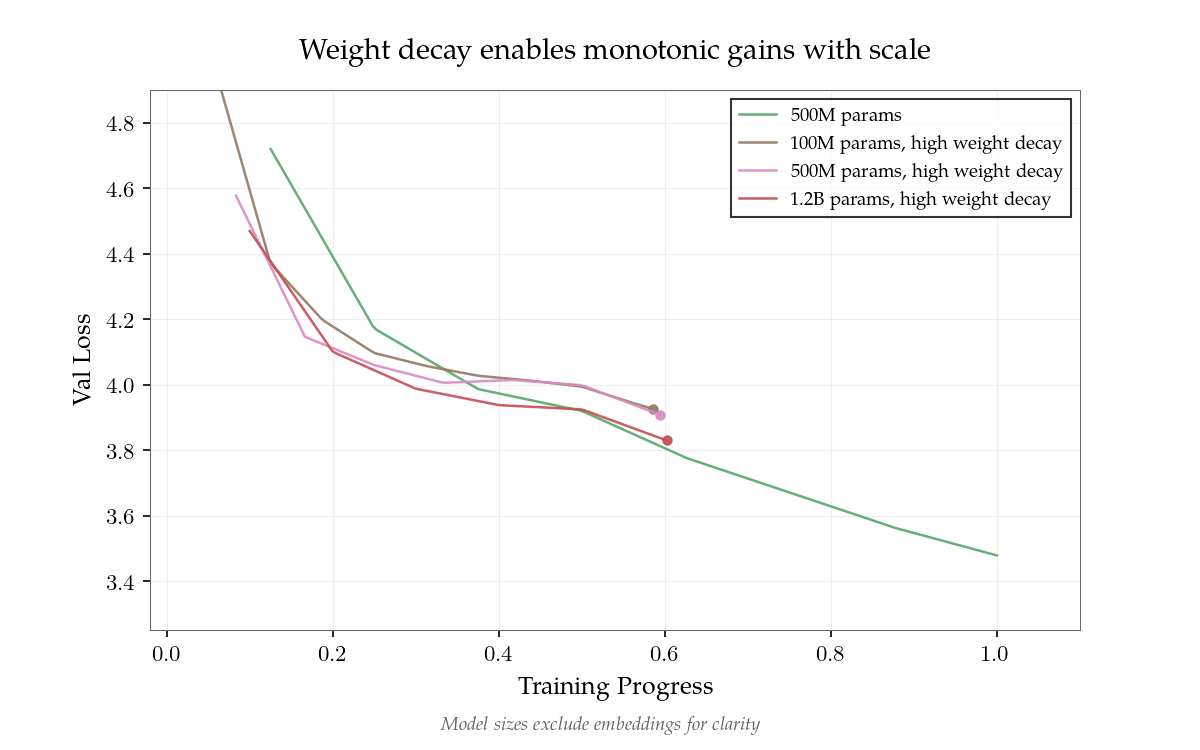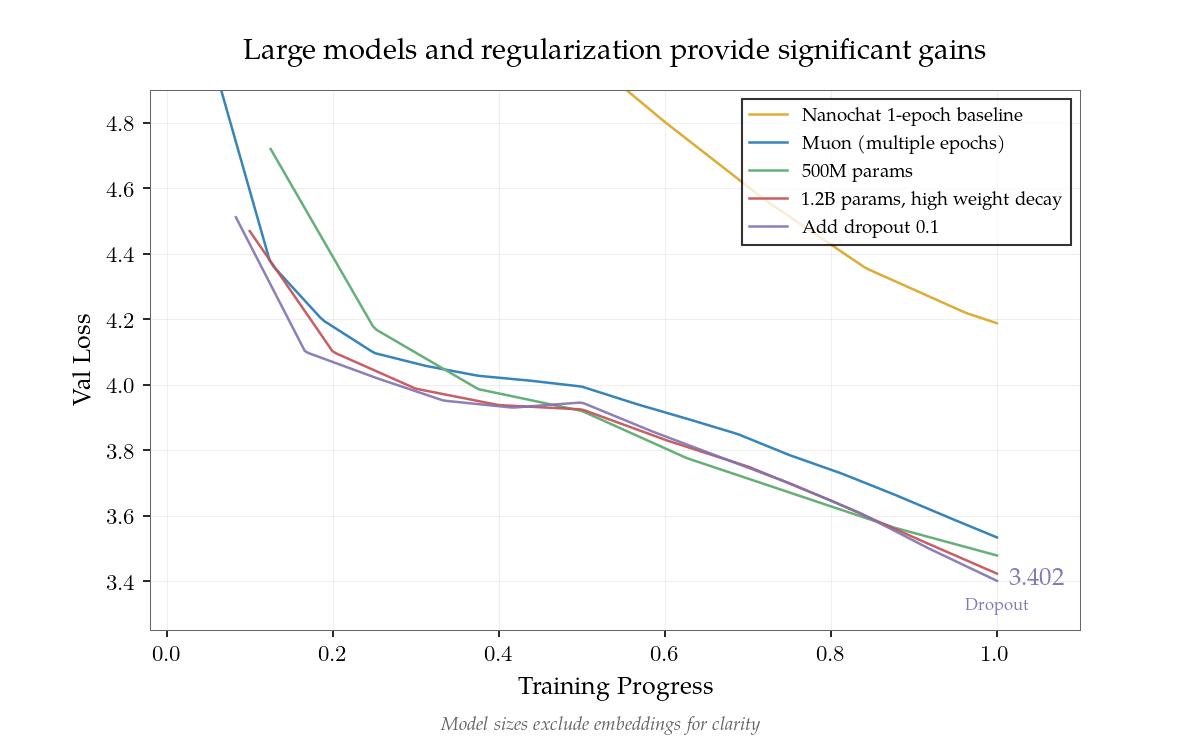
Data Scarcity as the Emerging Bottleneck in AI Scaling and Intelligence Development
Insight
qlabs.sh2mo ago