KV - Reduced minimum cache TTL for Workers KV to 30 seconds
5mo ago
Source
CloudflareKV - Reduced minimum cache TTL for Workers KV to 30 secondscloudflare.comThe minimum cacheTtl parameter for Workers KV has been reduced from 60 seconds to 30 seconds. This change applies to both get() and getWithMetadata() methods. This reduction allows you to maintain more up-to-date cached data and have finer-grained control over cache behavior. Applications requiring faster data refresh rates can now configure cache durations as low as 30 seconds instead of the previous 60-second minimum. The cacheTtl parameter defines how long a KV result is cached at the global network location it is accessed from: // Read with custom cache TTL const value = await env . NAMESPACE . get ( "my-key" , { cacheTtl : 30 , // Cache for minimum 30 seconds (previously 60) } ) ; // getWithMetadata also supports the reduced cache TTL const valueWithMetadata = await env . NAMESPACE . getWithMetadata ( "my-key" , { cacheTtl : 30 , // Cache for minimum 30 seconds } ) ; The default cache TTL remains unchanged at 60 seconds. Upgrade to the latest version of Wrangler to be able to use 30 seconds cacheTtl . This change affects all KV read operations using the binding API. For more information, consult the Workers KV cache TTL documentation .
You might also wanna read

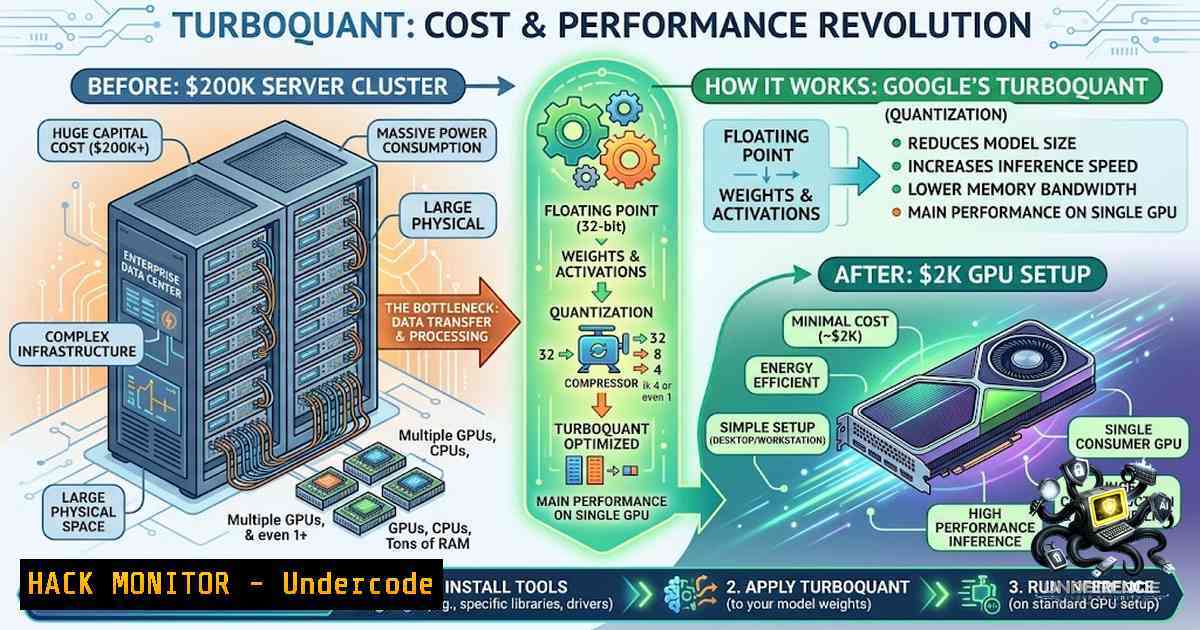
Google's TurboQuant Compresses LLM KV Cache Memory by 6x Without Accuracy Loss
Google Research has introduced TurboQuant, a training-free compression algorithm presented at ICLR 2026 that dramatically reduces the memory
 undercodetesting.com·12d ago
undercodetesting.com·12d ago
Precomputing KV Caches Could Dramatically Reduce AI Agent Compute Costs
This article proposes a radical efficiency improvement for AI agents: instead of each agent recomputing the key-value (KV) cache from scratc
CacheKit: High-Performance Cache Policies and Data Structures for Rust Systems
CacheKit is a Rust library providing high-performance cache replacement policies and supporting data structures for systems programming. It
 github.com·5mo ago
github.com·5mo ago
FLUX.2 [dev] API Provider Benchmark: Latency, Speed & Price Comparison
A benchmarking and comparison analysis of API providers serving the FLUX.2 [dev] model, measuring latency, generation time, and pricing acro
 artificialanalysis.ai·1d ago
artificialanalysis.ai·1d ago
GitHub - LMCache/LMCache: LMCache: Supercharge Your LLM with the Fastest KV Cache Layer
github.com·20d ago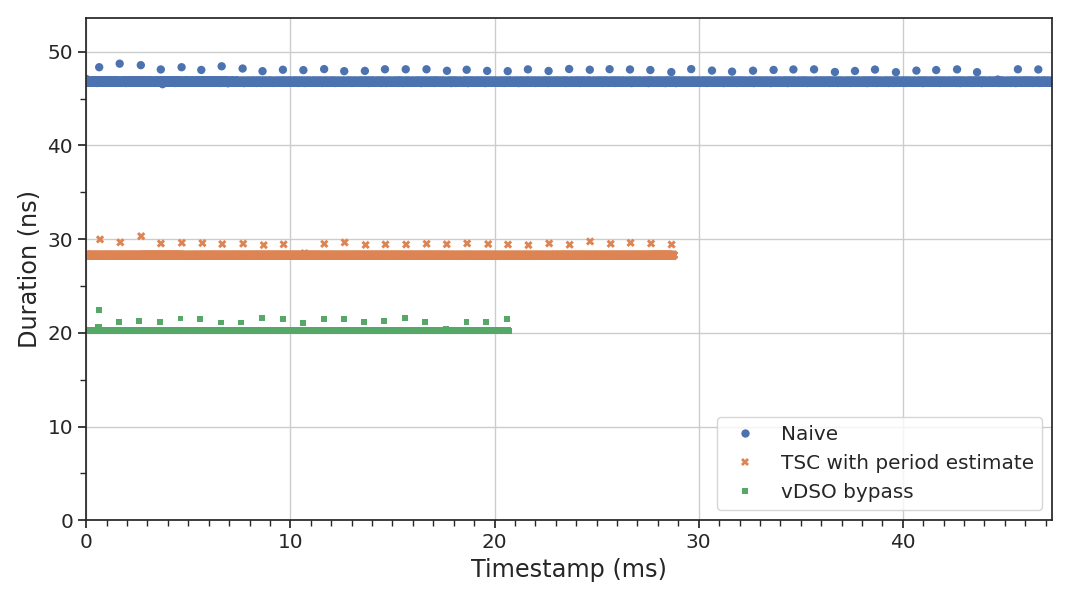
Optimizing Linux timestamps on x86: 30% faster custom timers without vDSO
A deep technical exploration of optimizing Linux timestamps on x86 architecture, achieving 30% speed improvements over standard system clock
 hmpcabral.com·2mo ago
hmpcabral.com·2mo ago
Comments
Sign in to join the conversation.
No comments yet. Be the first.