NVIDIA Releases Kimi-K2.6 DFlash Language Model with Speculative Decoding on Hugging Face
Summary
NVIDIA has released the Kimi-K2.6 DFlash model on Hugging Face, a draft head for Moonshot AI's Kimi-K2.6 auto-regressive language model. It uses an optimized transformer architecture and incorporates DFlash speculative decoding with Model Optimizer. The model is available for both commercial and non-commercial use under the NVIDIA Open Model License with a Modified MIT License.
Source
 Twitter / XNVIDIA Releases Kimi-K2.6 DFlash Language Model with Speculative Decoding on Hugging Facehuggingface.co
Twitter / XNVIDIA Releases Kimi-K2.6 DFlash Language Model with Speculative Decoding on Hugging Facehuggingface.coKey quotes
· 3 pulledThe NVIDIA Kimi-K2.6 DFlash model is the DFlash draft head of Moonshot AI's Kimi-K2.6 model, which is an auto-regressive language model that uses an optimized transformer architecture.
This model is ready for commercial/non-commercial use.
We're on a journey to advance and democratize artificial intelligence through open source and open science.
You might also wanna read

Moonshot AI Develops Kimi K2: A Cutting-Edge Language Model with 32 Billion Parameters
Kimi K2 is a state-of-the-art mixture-of-experts (MoE) language model with 32 billion activated parameters and 1 trillion total parameters d
github.com·11mo ago

NVIDIA Tests DFlash, a Block-Diffusion Method to Accelerate LLM Inference on GPUs
NVIDIA is testing DFlash, a new method that accelerates LLM inference by replacing sequential speculative drafting with a block-diffusion mo
 stechtimes.com·5d ago
stechtimes.com·5d ago
Moonshot Kimi-K2.5 Technical Documentation and GitHub AI Development Tools Overview
The article appears to be a technical report or documentation for Moonshot's Kimi-K2.5 AI model, hosted on GitHub. It includes information a
github.com·5mo ago
NVIDIA Unveils RTX Spark PCs for Local AI Agents at GTC Taipei
NVIDIA announced RTX Spark, a new class of Windows PCs designed for running personal AI agents locally, at GTC Taipei at COMPUTEX. The annou
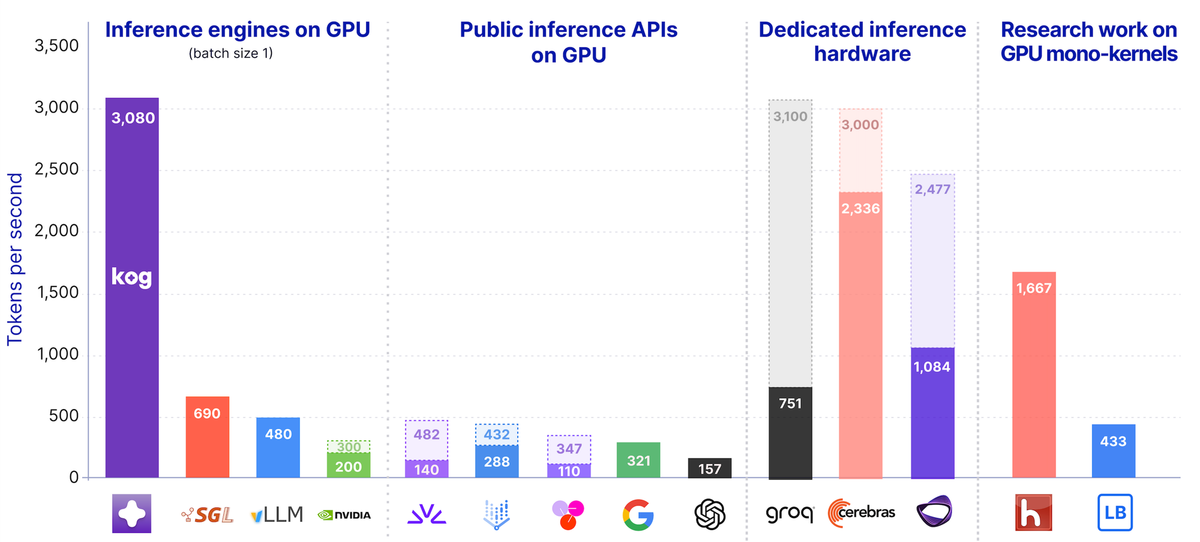
Kog AI Launches Inference Engine Tech Preview: 3,000 Tokens/s on AMD MI300X GPUs
Kog AI launches a tech preview of the Kog Inference Engine (KIE), achieving 3,000 output tokens/s per request on 8× AMD MI300X GPUs and 2,10
Kimi Linear: Hybrid Linear Attention Architecture for Efficient AI Models
Kimi Linear is a hybrid linear attention architecture for AI models that achieves significant performance improvements and speedups. It demo
github.com·8mo ago
Comments
Sign in to join the conversation.
No comments yet. Be the first.