KernelBench-Mega: Open Benchmark for Agentic GPU Whole-Block Megakernel Performance
By
Elliot Arledge
Summary
KernelBench-Mega is an open benchmark for agentic GPU kernel generation, testing whole-block megakernels that fuse entire model blocks into a single kernel. The benchmark evaluates performance on GPUs like RTX PRO 6000 Blackwell, H100, and B200, using metrics such as decode speedup over an optimized-PyTorch baseline (e.g., 19.35x) and tokens per second. The article specifically highlights the Problem 02_kimi_linear_decode task, a Kimi-Linear W4A16 hybrid decode operation.
Source
Key quotes
· 3 pulledKernelBench-Mega tests whole-block megakernels: instead of grading a single isolated op, the agent fuses an entire model block into one kernel.
The headline metric is the decode speedup over an optimized-PyTorch baseline (e.g. 19.35x = 19x faster than the reference), not a 0-1 roofline fraction.
Problem 02_kimi_linear_decode is a Kimi-Linear W4A16 hybrid decode (4-bit weights, bf16 activations).
You might also wanna read


MegaTrain: System for Training 100B+ Parameter LLMs on Single GPU Using CPU Memory
MegaTrain is a memory-centric system that enables training of 100B+ parameter large language models at full precision on a single GPU by sto

NVIDIA Blackwell Leads First Agentic AI Benchmark from Artificial Analysis
Artificial Analysis launched AgentPerf, the industry's first benchmark for agentic AI workloads. The initial results show NVIDIA's Blackwell

AI-Generated Metal Kernels Accelerate PyTorch Inference by 87% on Apple Devices
Researchers developed AI-generated Metal kernels that accelerate PyTorch inference on Apple devices by 87% across 215 modules. The study dem
 gimletlabs.ai·10mo ago
gimletlabs.ai·10mo ago
AutoKernel: Autonomous AI System for GPU Kernel Optimization in PyTorch Models
AutoKernel is an autonomous AI system that automatically optimizes GPU kernels for PyTorch models. Inspired by autonomous AI research agents
 github.com·3mo ago
github.com·3mo ago
TileMaxSim: IO-Aware GPU Kernels Achieve 80% HBM Bandwidth for Multi-Vector Retrieval Scoring
This paper presents TileMaxSim, a family of IO-aware GPU kernels for accelerating MaxSim scoring in multi-vector retrieval models like ColBE
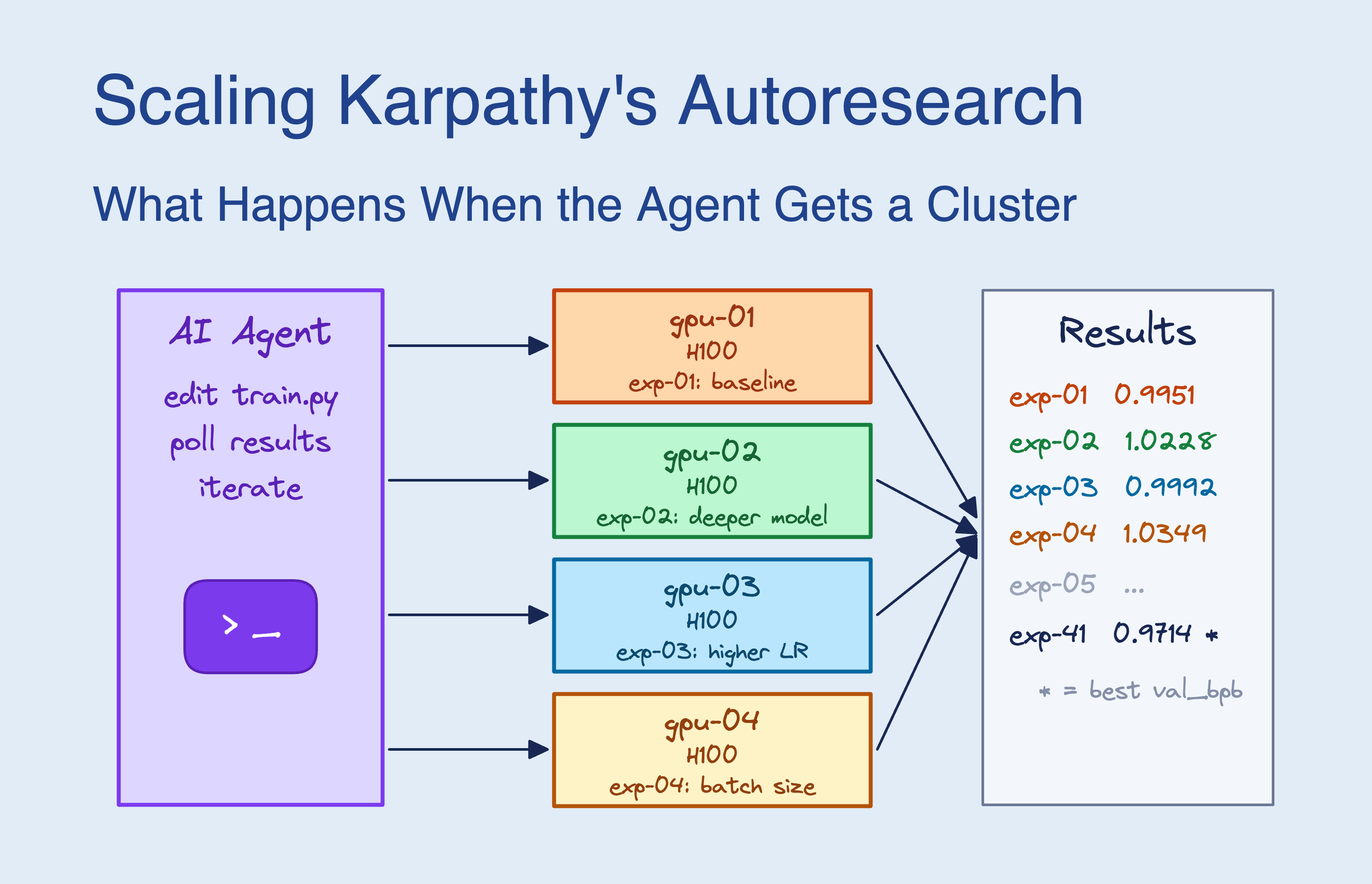
Scaling Karpathy's Autoresearch: Parallel GPU Processing Enables New AI Experimentation Strategies
The article describes an experiment where researchers scaled Andrej Karpathy's autoresearch system by giving it access to 16 GPUs on a Kuber
 blog.skypilot.co·3mo ago
blog.skypilot.co·3mo ago
Comments
Sign in to join the conversation.
No comments yet. Be the first.