Exploring Model Graders for Reinforcement Fine-Tuning
1y ago
Source
 OpenAIExploring Model Graders for Reinforcement Fine-Tuningopenai.com
OpenAIExploring Model Graders for Reinforcement Fine-Tuningopenai.comCookbook to use model graders for reinforcement fine-tuning in expert tasks.
You might also wanna read


Understanding Reinforcement Learning for Model Training, and future directions with GRAPE
Reinforcement Learning to Train Large Language Models to Explain Human Decisions
arxiv.org·1y ago

Supervised Fine-Tuning as Reinforcement Learning: Introducing Importance-Weighted SFT
The article explores the connection between supervised fine-tuning (SFT) of large language models and reinforcement learning (RL), arguing t

JAMEL: A Framework for Joint Memory and Exploration Learning in Language Model Agents
This paper introduces JAMEL (Joint Agent Memory and Exploration Learning), a framework that trains language model agents to explore open-end

Study reveals why in-context learning fails on complex specification-heavy tasks and how fine-tuning can help
This research paper investigates the limitations of in-context learning (ICL) for large language models (LLMs) when applied to specification
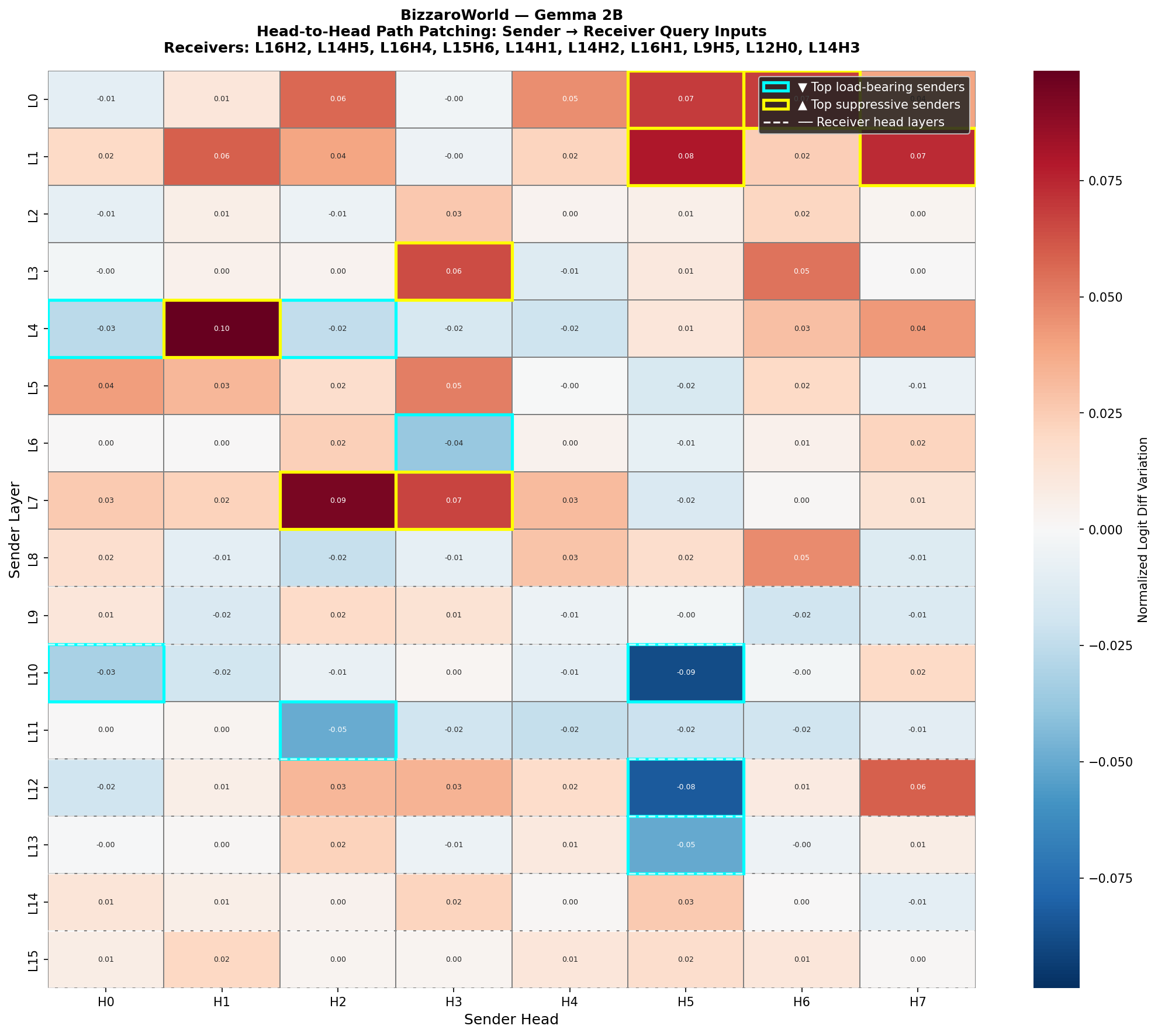
Localizing Factual Recall Circuits in Gemma Models via Activation Patching
This article presents BizzaroWorld, a mechanistic interpretability study that localizes factual recall circuits in the Gemma-2B and Gemma-12
 towardsdatascience.com·6d ago
towardsdatascience.com·6d ago
Comments
Sign in to join the conversation.
No comments yet. Be the first.