Localizing Factual Recall Circuits in Gemma Models via Activation Patching
By
Subhanga Upadhyay
Summary
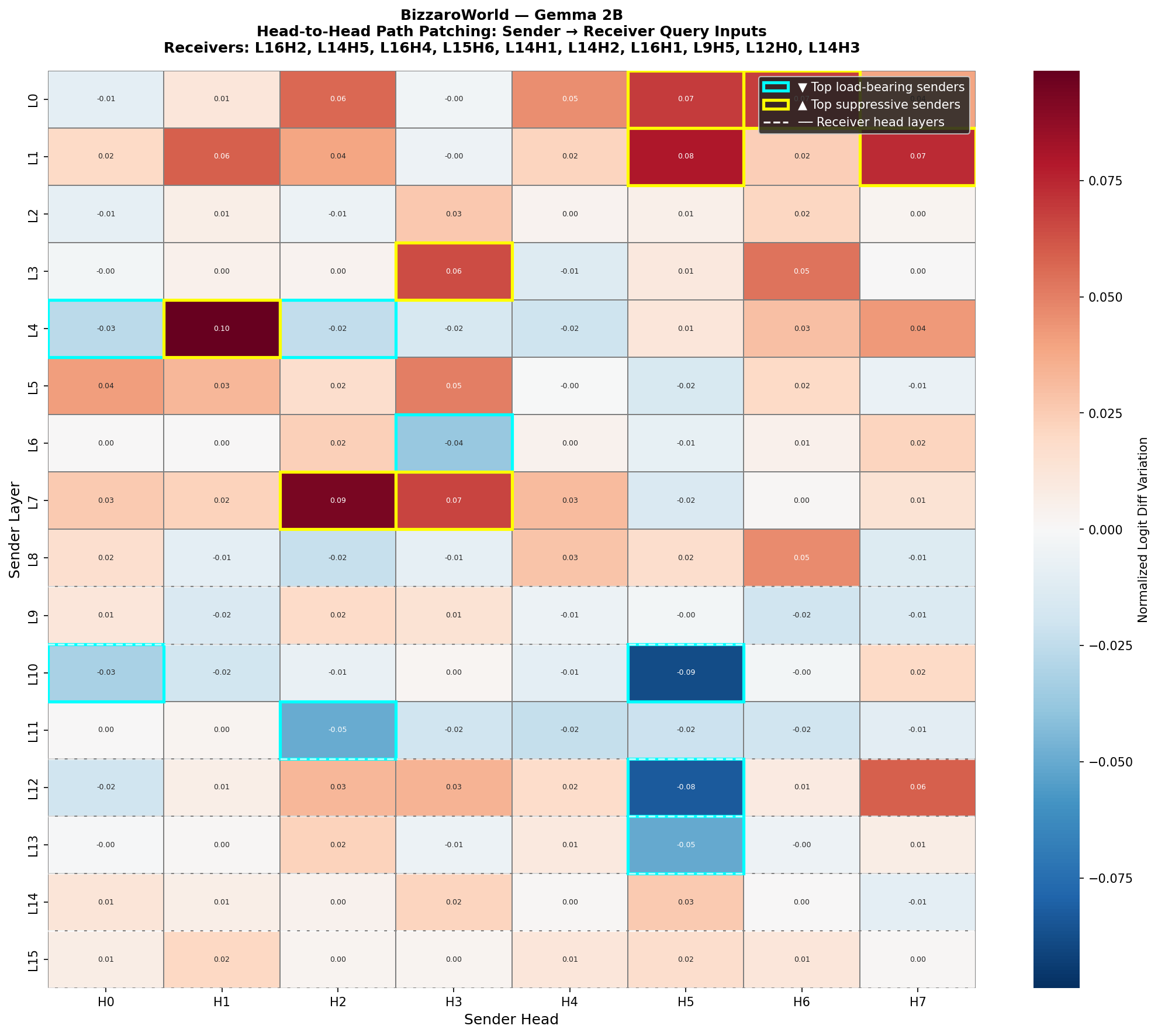
This article presents BizzaroWorld, a mechanistic interpretability study that localizes factual recall circuits in the Gemma-2B and Gemma-12B-IT models using activation patching across 60 prompt pairs and 20 knowledge categories. The research investigates how factual knowledge is stored, routed, and read out across transformer layers, finding that the residual stream does most of the work. The study is influenced by prior work on entity tracking in the LLaMa model series and aims to determine whether factual knowledge localization is consistent across model scales.
Source
 bskyLocalizing Factual Recall Circuits in Gemma Models via Activation Patchingtowardsdatascience.com
bskyLocalizing Factual Recall Circuits in Gemma Models via Activation Patchingtowardsdatascience.comKey quotes
· 3 pulledThis post presents BizzaroWorld, a mechanistic interpretability study attempting to localize factual recall circuits in the Gemma model family using activation patching across 60 prompt pairs and 20 knowledge categories.
The goal: localize where factual knowledge lives inside a transformer, and whether that location is consistent across model scale.
Activation patching reveals how facts are stored, routed, and read out across transformer layers, and why the residual stream does most of the work
You might also wanna read


Research: 224× Compression of Llama-70B Achieved with Improved Accuracy Through Meaning Field Extraction
This research paper introduces a novel method for eliminating transformers from inference while maintaining or improving accuracy. The appro
 zenodo.org·6mo ago
zenodo.org·6mo ago
Ouro: Looped Language Models That Build Reasoning into Pre-Training Through Latent Space Iteration
Researchers introduce Ouro, a family of pre-trained Looped Language Models (LoopLM) that build reasoning capabilities directly into the pre-

Comprehensive Survey of Reasoning Failures in Large Language Models
This article presents a comprehensive survey of reasoning failures in Large Language Models (LLMs), introducing a novel categorization frame

Study Finds Single Transformer Layer Can Match Full-Parameter RL Training in LLMs
This research paper challenges the common assumption that reinforcement learning (RL) post-training for large language models (LLMs) require
Study Finds Single Transformer Layer Can Match Full-Parameter RL Training in LLMs
This research paper challenges the common assumption that reinforcement learning (RL) post-training for large language models (LLMs) require

Neural Procedural Memory: Using Implicit Activation Steering to Improve LLM Agent Memory Without Training
This paper introduces Neural Procedural Memory (NPM), a training-free framework for LLM agents that replaces explicit textual instructions (
Neural Procedural Memory: Using Implicit Activation Steering to Improve LLM Agent Memory Without Training
This paper introduces Neural Procedural Memory (NPM), a training-free framework for LLM agents that replaces explicit textual instructions (
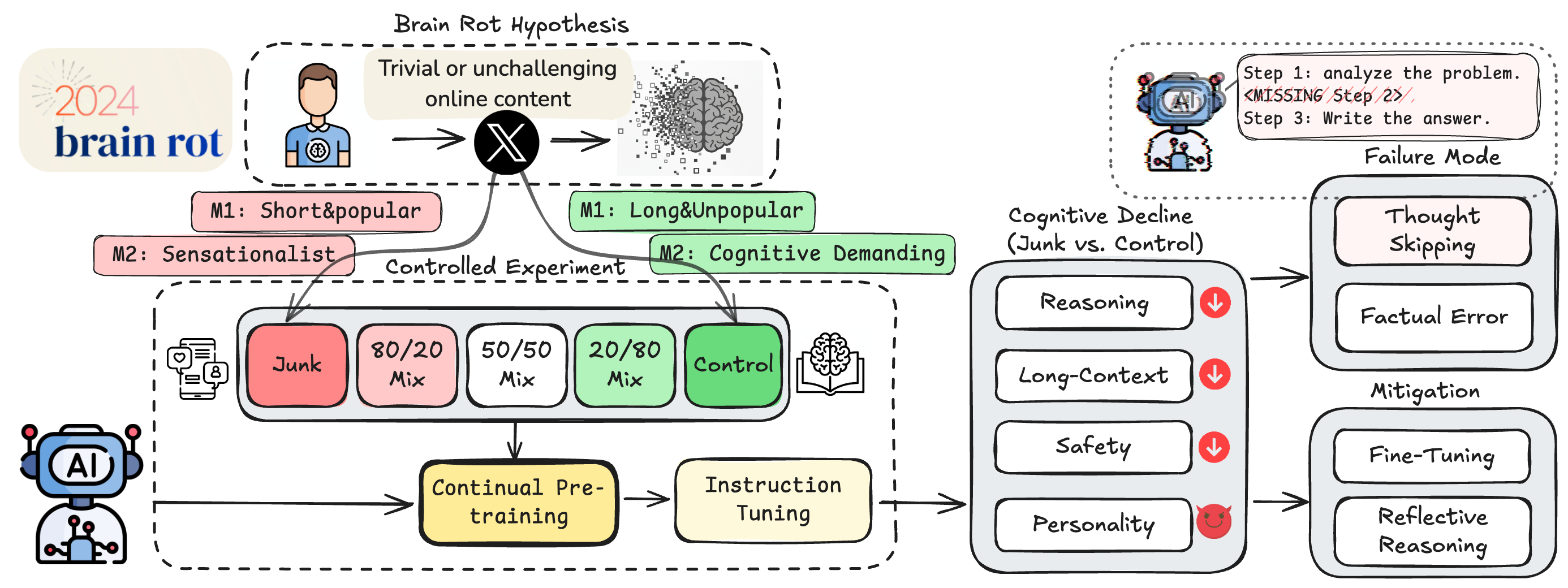
Research Shows LLMs Develop Cognitive Degradation from Social Media Training Data
This research paper introduces the concept of 'LLM Brain Rot' - a phenomenon where large language models (LLMs) experience cognitive degrada
Comments
Sign in to join the conversation.
No comments yet. Be the first.