Evals Best Practices
Source
 OpenAIEvals Best Practicesopenai.com
OpenAIEvals Best Practicesopenai.comYou might also wanna read


PPT-Eval: A Benchmark for Evaluating AI Agents on PowerPoint Creation and Editing Tasks
PPT-Eval is a benchmark introduced for evaluating computer-use AI agents on PowerPoint tasks. It consists of 120 tasks across 12 PowerPoint
 microsoft.github.io·2d ago
microsoft.github.io·2d ago
The Essential Role of Manual Data Review in AI Agent Evaluation
The article discusses the importance of evaluating AI agents, emphasizing that while automated evaluations (evals) are essential for testing
agent-skills-eval: An open-source test framework for measuring AI agent skill effectiveness
agent-skills-eval is an open-source test runner for evaluating AI agent skills (SKILL.md files) based on the Agent Skills standard from Anth
 GitHub·1mo ago
GitHub·1mo ago
BINEVAL: A Binary Question Framework for Interpretable LLM Evaluation and Self-Improvement
This paper introduces BINEVAL, a framework for evaluating LLM outputs that decomposes evaluation criteria into atomic binary questions. Inst
BINEVAL: A Binary Question Framework for Interpretable LLM Evaluation and Self-Improvement
This paper introduces BINEVAL, a framework for evaluating LLM outputs that decomposes evaluation criteria into atomic binary questions. Inst

A Practical Guide to Programming Language Design and Implementation
This article provides a comprehensive guide to programming language design, covering the iterative process of language creation through four
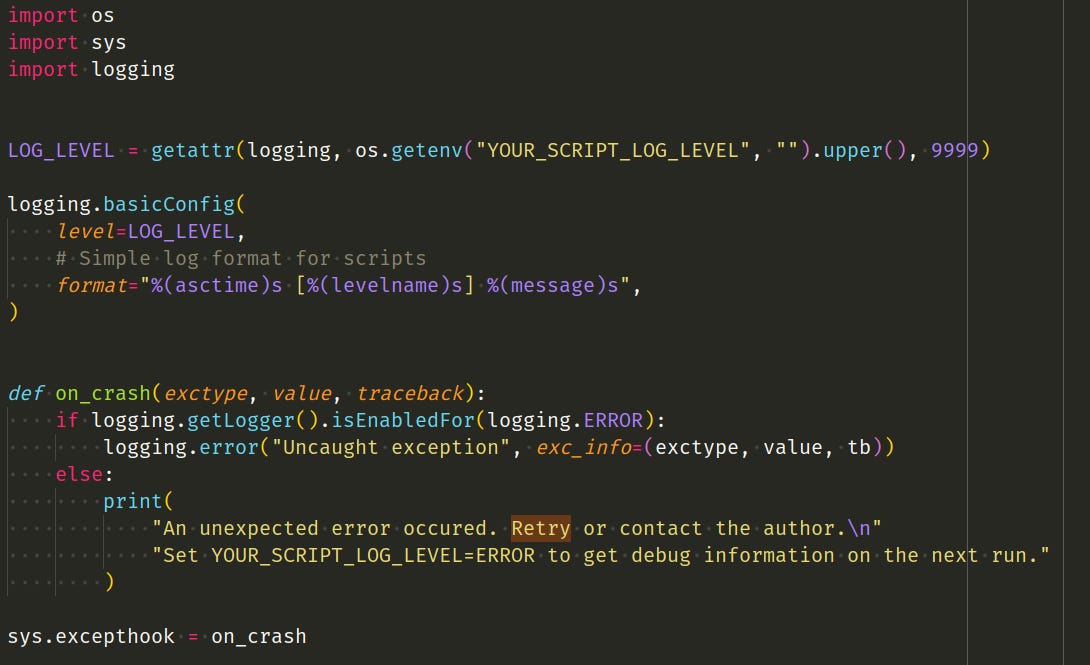
Python scripting best practices: improving code quality and maintainability
A practical guide on best practices for writing Python scripts, covering topics like using `if __name__ == "__main__"` guards, proper argume
 bitecode.dev·13d ago
bitecode.dev·13d ago
Comments
Sign in to join the conversation.
No comments yet. Be the first.