The Essential Role of Manual Data Review in AI Agent Evaluation
By
mfalcon
Warm and crisp on the edges. A bagel with a bit of bite.
Summary
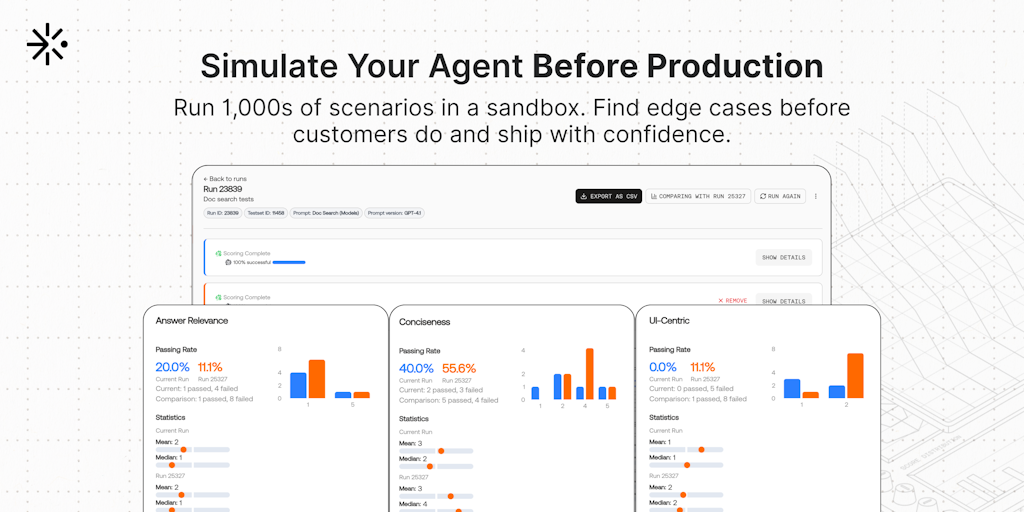
The article discusses the importance of evaluating AI agents, emphasizing that while automated evaluations (evals) are essential for testing, they cannot replace the need for manual review of agent traces and data. The author recommends starting with end-to-end evaluations that measure whether agents successfully meet user goals with simple yes/no outcomes, but stresses that human examination of the data remains crucial for identifying issues and improvements.
Key quotes
· 4 pulledNo amount of evals will replace the need to look at the data
Once you have good eval coverage you'll be able to decrease the time but it'll always be a must to just look at the agent traces
You must create evals for your agents, stop relying solely on manual testing
Define a success criteria (did the agent meet the user's goal?) and make the evals output a simple yes/no value
You might also wanna read

Scorecard CEO warns of AI agent dangers in high-stakes domains, offers evaluation platform
Darius, CEO of Scorecard, shares a cautionary tale about building AI agents in high-stakes domains. He describes how his EMR agent for docto
 Product Hunt·7mo ago
Product Hunt·7mo ago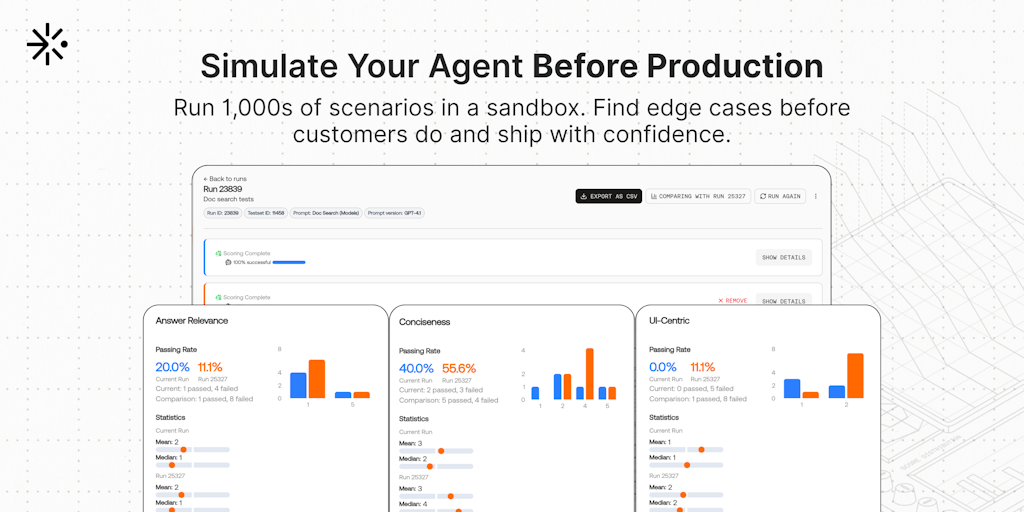
Scorecard: Platform for Evaluating and Optimizing AI Agents in High-Stakes Applications
The CEO of Scorecard shares a cautionary tale about nearly shipping a dangerous AI agent for doctors that confused pediatric and adult dosin
Product Hunt·7mo ago
Why AI-Driven Synthetic User Testing Fails: A Case for Real UX Research
The article argues against the growing trend of companies using AI-driven "synthetic" user testing as a replacement for real UX research wit
 Smashing Magazine·1y ago
Smashing Magazine·1y ago