Efficient Training Data Reduction Using High-Fidelity Labels and Human Expertise
By
badmonster
Right out the toaster. Reliable, with some real depth.
Summary
The article describes a process for achieving significant training data reduction by using a zero- or few-shot initial model (LLM-0) to label data, followed by clustering and human expert review to curate the most informative and diverse examples. This method addresses the imbalance and low true positive rate of the initial model by focusing on confusable examples along the decision boundary.
Key quotes
· 4 pulledOur process starts with a zero- or few-shot initial model (LLM-0), which we provide with a prompt describing the content of interest.
The LLM-0 model then labels ads as clickbait or benign and generates a large labeled data set.
To find the most informative examples, we separately cluster examples labeled clickbait and examples labeled benign.
The resulting curated set is both informative (since it contains the most confusable examples along the decision boundary) and diverse.
You might also wanna read


MLJAR Studio: A Private, Local AI Platform for Data Analysis and Machine Learning
MLJAR Studio is a private, locally-run AI data analysis platform that allows users to interact with their data using natural language, autom
 mljar.com·29d ago
mljar.com·29d ago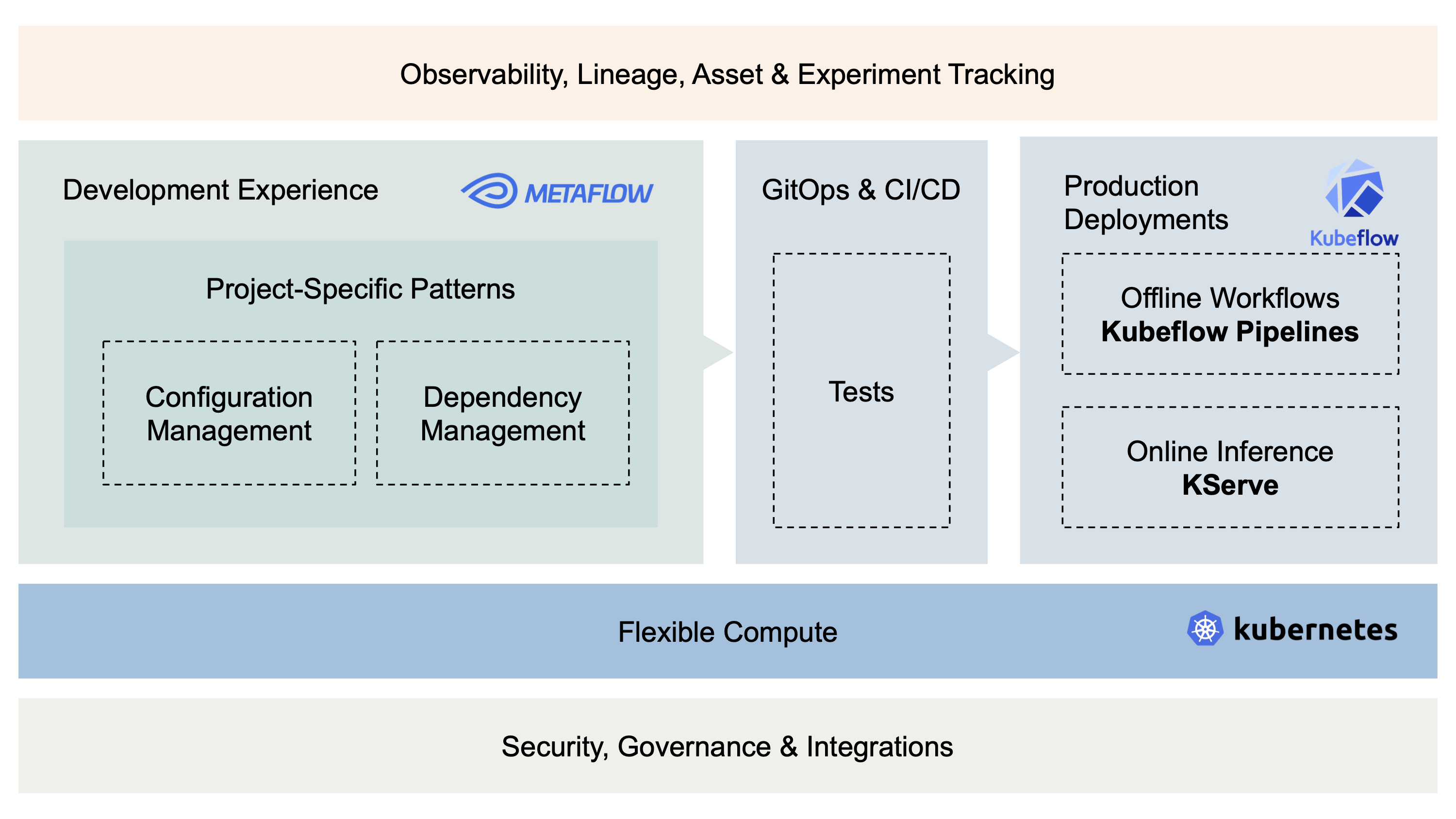
Metaflow and Kubeflow Integration: Combining Data Science Productivity with Scalable ML Infrastructure
The article introduces the integration between Metaflow and Kubeflow, two machine learning workflow frameworks. Metaflow, originally develop
 blog.kubeflow.org·3mo ago
blog.kubeflow.org·3mo ago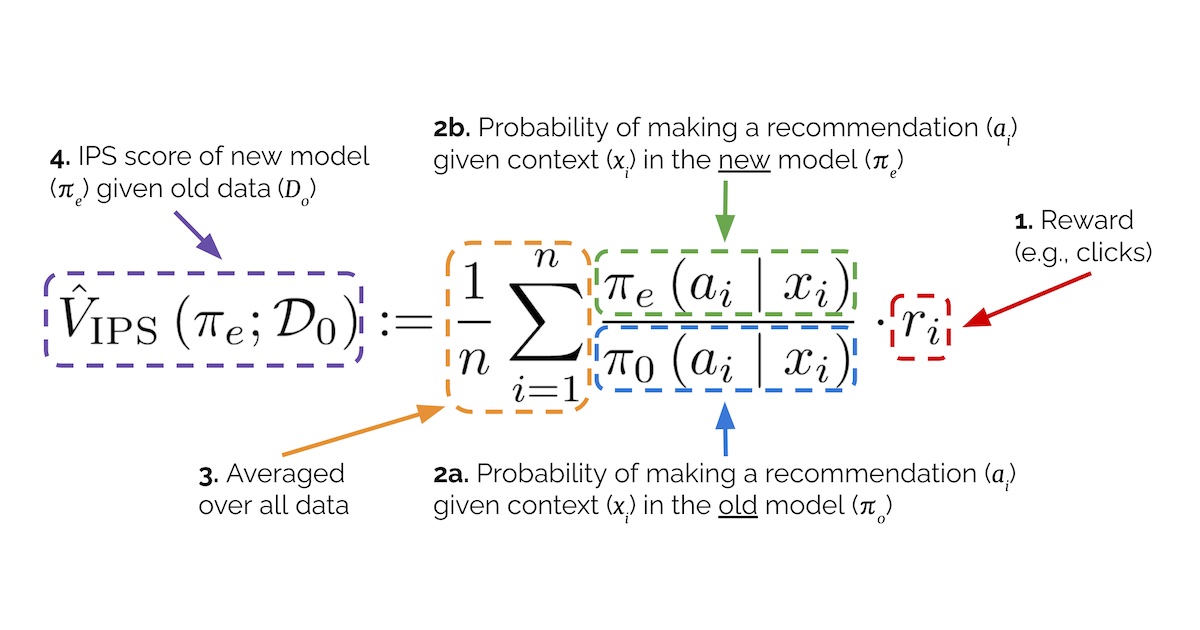
Counterfactual Evaluation Methods for Recommendation Systems: Addressing Causal Effects in Offline Assessment
This article discusses the limitations of traditional offline evaluation methods for recommendation systems, which treat recommendations as
 eugeneyan.com·4mo ago
eugeneyan.com·4mo ago
ClickHouse Releases Hacker News Vector Search Dataset with 28.7 Million Postings
ClickHouse has released a comprehensive vector search dataset containing 28.74 million Hacker News postings with their corresponding vector
 clickhouse.com·6mo ago
clickhouse.com·6mo ago
DeepSeek-V4: Hybrid Sparse-Attention Architecture Enables Efficient Million-Token Context Inference
DeepSeek-V4 introduces a hybrid sparse-attention architecture combined with on-policy distillation across domain specialists, enabling 1M-to
 artgor.medium.com·11h ago
artgor.medium.com·11h ago
Rotary GPU: Enabling Large Mixture-of-Experts Models on Consumer Laptop GPUs with Limited Memory
This paper presents Rotary GPU, an exploratory approach to running large Mixture-of-Experts (MoE) language models on consumer-grade hardware