ClickHouse Releases Hacker News Vector Search Dataset with 28.7 Million Postings
By
walterbell
Pure flour-power. Hearty enough to carry you through lunch.
Summary
ClickHouse has released a comprehensive vector search dataset containing 28.74 million Hacker News postings with their corresponding vector embeddings. The embeddings were generated using the SentenceTransformers model all-MiniLM-L6-v2, with each vector having 384 dimensions. The dataset is available as a single Parquet file in an S3 bucket and is designed to help users understand the design, sizing, and performance aspects of large-scale vector search applications built on user-generated textual data.
Key quotes
· 4 pulledThe Hacker News dataset contains 28.74 million postings and their vector embeddings.
The embeddings were generated using SentenceTransformers model all-MiniLM-L6-v2. The dimension of each embedding vector is 384.
This dataset can be used to walk through the design, sizing and performance aspects for a large scale, real world vector search application built on top of user generated, textual data.
The complete dataset with vector embeddings is made available by ClickHouse as a single Parquet file in a S3 bucket.
You might also wanna read


MLJAR Studio: A Private, Local AI Platform for Data Analysis and Machine Learning
MLJAR Studio is a private, locally-run AI data analysis platform that allows users to interact with their data using natural language, autom
 mljar.com·29d ago
mljar.com·29d ago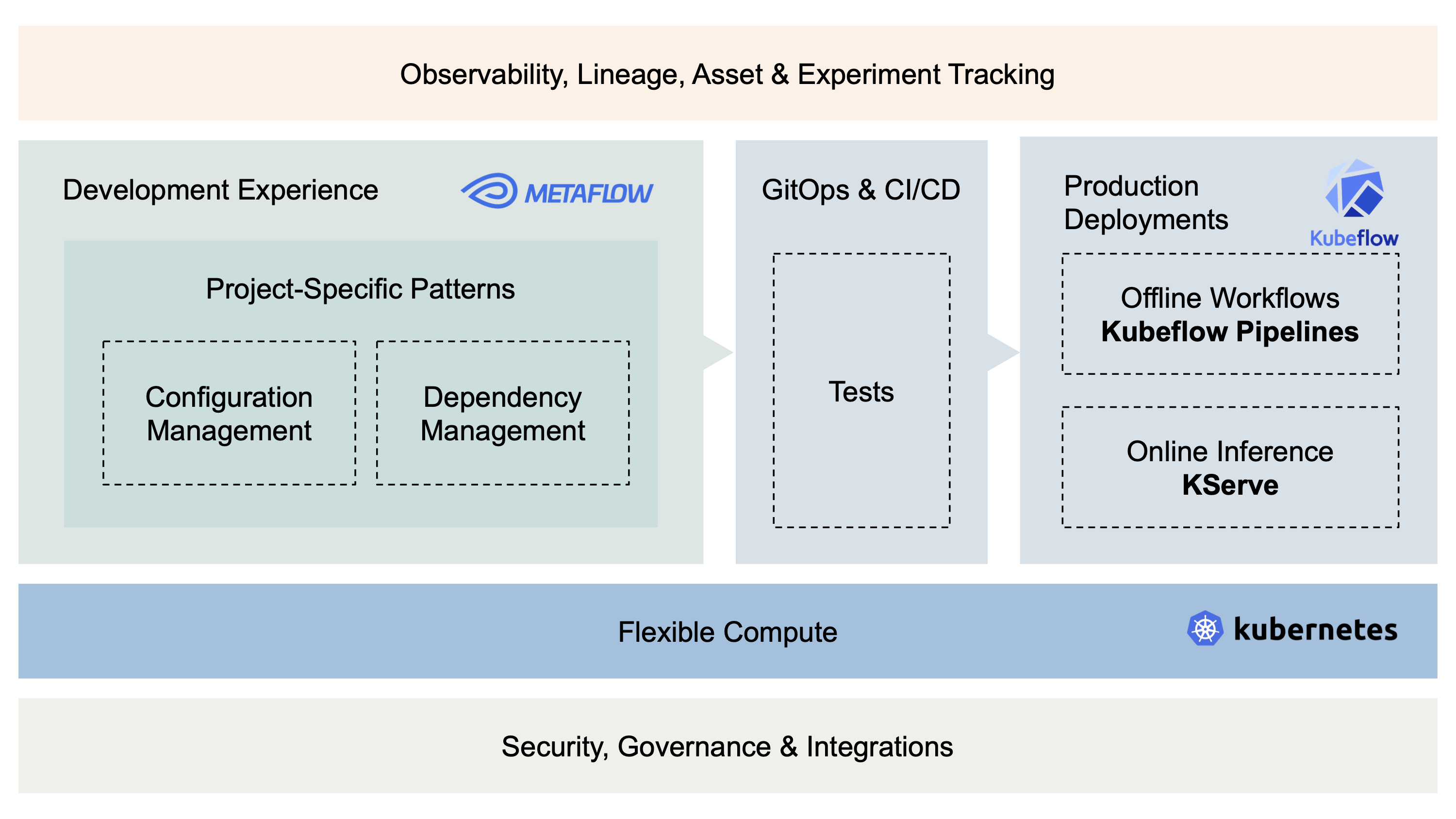
Metaflow and Kubeflow Integration: Combining Data Science Productivity with Scalable ML Infrastructure
The article introduces the integration between Metaflow and Kubeflow, two machine learning workflow frameworks. Metaflow, originally develop
 blog.kubeflow.org·3mo ago
blog.kubeflow.org·3mo ago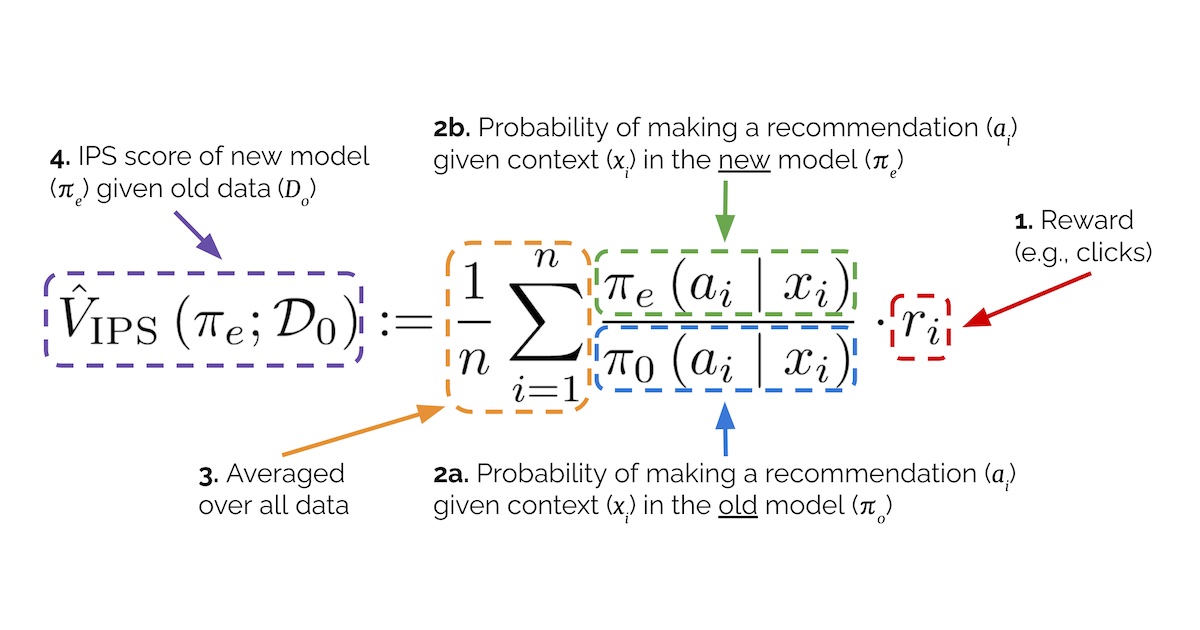
Counterfactual Evaluation Methods for Recommendation Systems: Addressing Causal Effects in Offline Assessment
This article discusses the limitations of traditional offline evaluation methods for recommendation systems, which treat recommendations as
 eugeneyan.com·4mo ago
eugeneyan.com·4mo ago
Efficient Training Data Reduction Using High-Fidelity Labels and Human Expertise
The article describes a process for achieving significant training data reduction by using a zero- or few-shot initial model (LLM-0) to labe
 research.google·9mo ago
research.google·9mo ago
DeepSeek-V4: Hybrid Sparse-Attention Architecture Enables Efficient Million-Token Context Inference
DeepSeek-V4 introduces a hybrid sparse-attention architecture combined with on-policy distillation across domain specialists, enabling 1M-to
 artgor.medium.com·11h ago
artgor.medium.com·11h ago
Rotary GPU: Enabling Large Mixture-of-Experts Models on Consumer Laptop GPUs with Limited Memory
This paper presents Rotary GPU, an exploratory approach to running large Mixture-of-Experts (MoE) language models on consumer-grade hardware