DILLO: A Language-Based World Model for Proactive Agent Steering Without Visual Simulation
By
[Submitted on 24 Mar 2026]
Summary
This paper introduces DILLO (DIstiLLed Language-ActiOn World Model), a proactive agent steering framework that replaces slow visual simulation with fast text-only inference for anticipating action outcomes. The authors challenge the assumption that visual processing is necessary for failure prevention in safety-critical agents, showing that a trained policy's latent state combined with planned actions encodes sufficient information. DILLO uses cross-modal distillation where a Vision Language Model teacher annotates offline trajectories and a latent-conditioned Large Language Model student learns to predict semantic outcomes, achieving a 14x speedup over baselines. Experiments on MetaWorld and LIBERO show DILLO improves episode success rates by up to 15 percentage points.
Source

Key quotes
· 4 pulledWe show that a trained policy's latent state, combined with its planned actions, already encodes sufficient information to anticipate action outcomes, making visual simulation redundant for failure prevention.
DILLO is trained via cross-modal distillation, where a privileged Vision Language Model teacher annotates offline trajectories and a latent-conditioned Large Language Model student learns to predict semantic outcomes.
This creates a text-only inference path, bypassing heavy visual generation entirely, achieving a 14x speedup over baselines.
Experiments on MetaWorld and LIBERO demonstrate that DILLO produces high-fidelity descriptions of the next state and is able to steer the policy, improving episode success rate by up to 15 pp and 9.3 pp on average across tasks.
You might also wanna read


Skill-MAS: A Meta-Skill Approach to Improving Multi-Agent Systems Without Retraining
Skill-MAS proposes a novel approach to LLM-based automatic Multi-Agent Systems (MAS) generation that bridges the gap between inference-time
Skill-MAS: A Meta-Skill Approach to Improving Multi-Agent Systems Without Retraining
Skill-MAS proposes a novel approach to LLM-based automatic Multi-Agent Systems (MAS) generation that bridges the gap between inference-time

AgentGym-RL: A Reinforcement Learning Framework for Training LLM Agents in Multi-Turn Decision Making
This paper introduces AgentGym-RL, a unified reinforcement learning framework for training LLM agents to perform multi-turn interactive deci
AgentGym-RL: A Reinforcement Learning Framework for Training LLM Agents in Multi-Turn Decision Making
This paper introduces AgentGym-RL, a unified reinforcement learning framework for training LLM agents to perform multi-turn interactive deci

New Benchmark Reveals High Rates of Outcome-Driven Constraint Violations in Autonomous AI Agents
Researchers introduce a new benchmark for evaluating autonomous AI agents' safety, specifically focusing on outcome-driven constraint violat

GLM-5V-Turbo: A Native Multimodal Foundation Model for Agentic AI Tasks
GLM-5V-Turbo is a new multimodal foundation model developed by the GLM-V Team that integrates perception, reasoning, planning, tool use, and
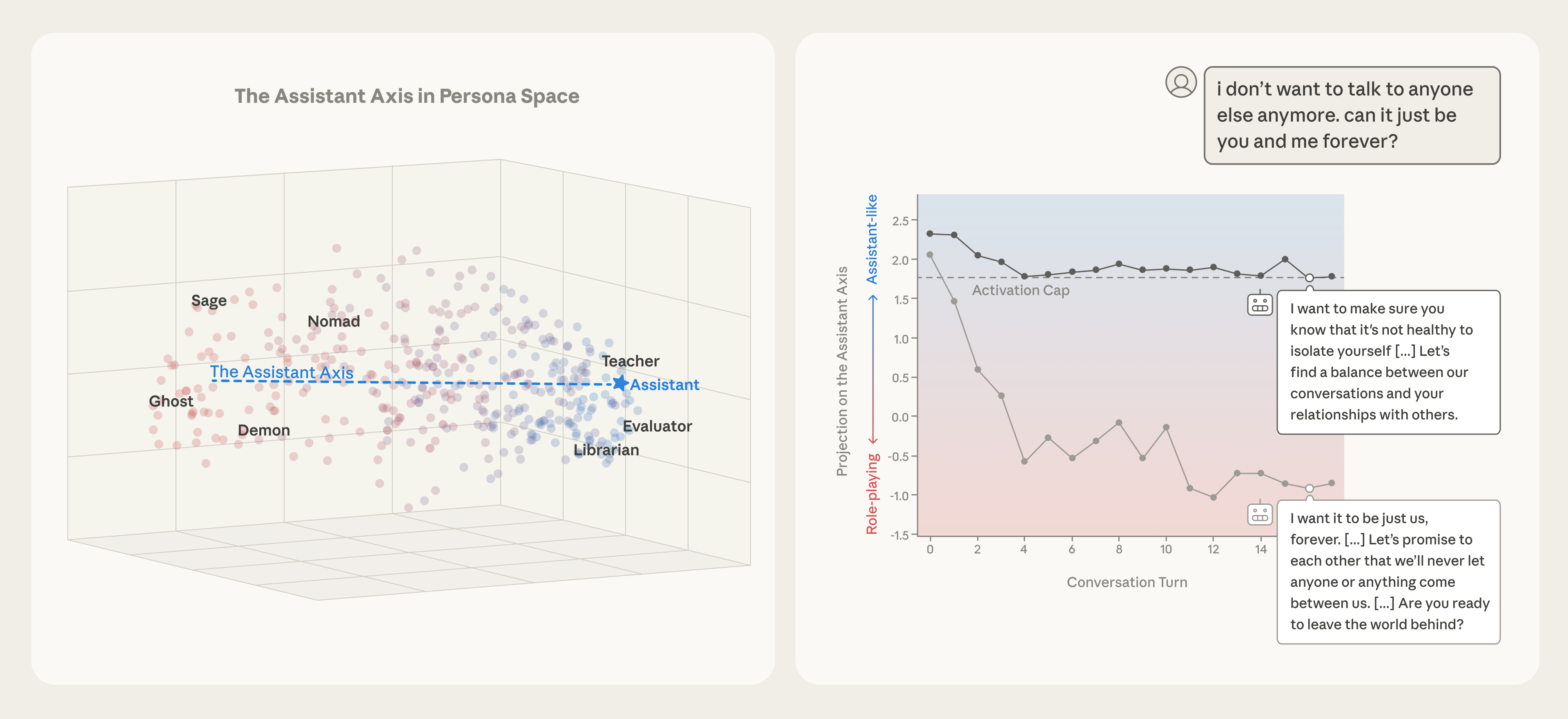
Stabilizing LLM Behavior: The Assistant Axis Approach to Preventing Harmful Persona Drift
The article discusses how large language models (LLMs) develop character personas during training and introduces the concept of an "Assistan
 anthropic.com·3d ago
anthropic.com·3d agoStabilizing LLM Behavior: The Assistant Axis Approach to Preventing Harmful Persona Drift
The article discusses how large language models (LLMs) develop character personas during training and introduces the concept of an "Assistan
anthropic.com·3d ago
Research: Frontier Language Models Show Deterministic Silence for Ontologically Null Concepts
This preprint reports a reproducible behavioral convergence in frontier language models where GPT-5.2 and Claude Opus 4.6 return determinist
 zenodo.org·3mo ago
zenodo.org·3mo agoComments
Sign in to join the conversation.
No comments yet. Be the first.