GLM-5V-Turbo: A Native Multimodal Foundation Model for Agentic AI Tasks
We present GLM-5V-Turbo, a step toward native foundation models for multimodal agents. As foundation models are increasingly deployed in real environments, agentic capability depends not only on…
Read the full articleYou might also wanna read

Cognitive-structured Multimodal Agent for Multimodal Understanding, Generation, and Editing
arXiv:2607.08497v1 Announce Type: cross Abstract: Recent unified multimodal models show a single architecture can jointly perform vision/lan
Grounding VLMs: VAORA's Leap in Physical AI
VAORA, a novel reward design, tackles VLM hallucination and reasoning-action misalignment in physical tasks, significantly improving general
UniClawBench: A Universal Benchmark for Proactive Agents on Real-World Tasks
arXiv:2607.08768v1 Announce Type: new Abstract: The rapid development of large language models and multimodal large language models has acce
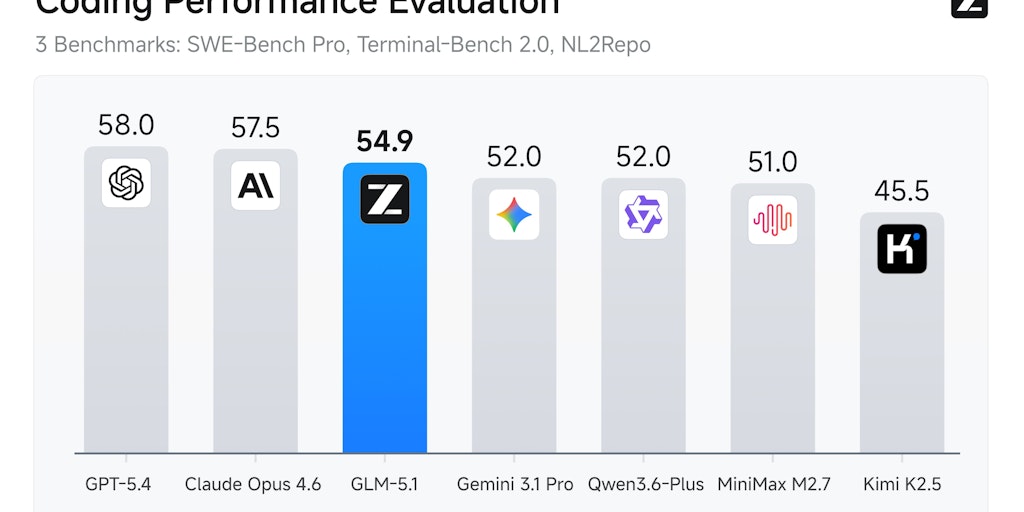
Z.ai Launches GLM-5.1 AI Model for Complex Agentic Coding Tasks
Official Z.ai platform to experience our new, MIT-licensed GLM models (Base, Reasoning, Rumination). Simple UI focuses on model interaction.
 Product Hunt·4mo ago
Product Hunt·4mo agoMCP and Multimodal AI: How Agents Handle Images, Video, Audio, and Rich Media
A comprehensive guide to multimodal content in MCP — covering ImageContent, AudioContent, EmbeddedResource content types, image generation s

Skill-MAS: A Meta-Skill Approach to Improving Multi-Agent Systems Without Retraining
Large Language Model (LLM)-based automatic Multi-Agent Systems (MAS) generation has become a crucial frontier for tackling complex tasks. Ho
Skill-MAS: A Meta-Skill Approach to Improving Multi-Agent Systems Without Retraining
Large Language Model (LLM)-based automatic Multi-Agent Systems (MAS) generation has become a crucial frontier for tackling complex tasks. Ho
Comments
Sign in to join the conversation.
No comments yet. Be the first.