Build a conversational protein research assistant with Amazon Bedrock AgentCore
Summary
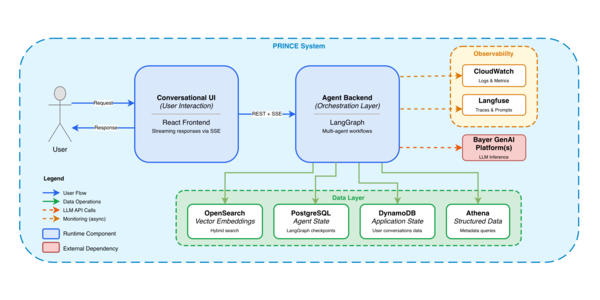
This article from Amazon Web Services provides a technical guide on building a conversational protein research copilot using Amazon Bedrock AgentCore. The system combines three key capabilities: natural language query parsing to extract structured search parameters, vector similarity search over protein embeddings using a specialized language model, and AI-generated scientific summaries of search results. The tool aims to help protein researchers overcome the time-consuming challenge of manually searching through thousands of peptide sequences to find structurally similar candidates, enabling natural language queries and automated embedding generation in a single conversational interface.
Source

 bskyBuild a conversational protein research assistant with Amazon Bedrock AgentCoreaws.amazon.com
bskyBuild a conversational protein research assistant with Amazon Bedrock AgentCoreaws.amazon.comKey quotes
· 3 pulledProtein researchers face a time-consuming challenge: manually searching through thousands of peptide sequences to find structurally similar candidates is slow, error-prone, and requires deep domain expertise to interpret results.
Building a protein research copilot can transform how researchers search for structurally similar peptides across large datasets — enabling natural language queries, automated embedding generation, and AI-powered result summarization in a single conversational interface.
This post shows you how to build a conversational protein research assistant that combines three capabilities: Natural language query parsing to extract structured search parameters, vector similarity search over protein embeddings using a specialized language model and ai-generated scientific summaries of search results.
You might also wanna read


Direct Corpus Interaction: A New Retrieval Paradigm for Agentic Search Without Embedding Models
This research paper introduces Direct Corpus Interaction (DCI), a novel approach to retrieval for agentic search that bypasses traditional e

Biohub Platform: ESM Protein Models, Atlas, and API for Biomolecular Research
This article presents the Biohub Platform, which offers a suite of tools built on the ESM family of protein language models. It highlights t
How LLMs Are Transforming Preclinical Drug Discovery Data Access
The article discusses how Large Language Models (LLMs) are being applied to preclinical drug discovery to help researchers efficiently acces

Paper2Agent: Converting Research Papers into Interactive AI Agents for Scientific Discovery
Paper2Agent is an automated framework that converts research papers into interactive AI agents, transforming static research outputs into ac
Building a Semantic Search Engine with PartyKit's Vector Database in 160 Lines of Code
The article explains how to build a highly effective search engine using PartyKit's new vector database and embedding model capabilities. It
 blog.partykit.io·6mo ago
blog.partykit.io·6mo ago
More Like This Search: From Keyword Matching to Embeddings and Vector Search
This article explores the evolution of "More Like This" (MLT) search functionality, which allows users to find documents similar to a select
 manticoresearch.com·19d ago
manticoresearch.com·19d ago
Comments
Sign in to join the conversation.
No comments yet. Be the first.