BIFE: A New Framework for Stable Minute-Long Video Generation Using Semantic Sparse KV Cache and Block Forcing
By
[Submitted on 28 Nov 2025 (v1), last revised 22 Jun 2026 (this version, v2)]
Summary
This paper introduces BIFE (Better Interaction, Fewer Errors), a framework for minute-long video generation that addresses two key challenges in autoregressive diffusion models: failure to preserve long-range interactions due to sliding-window KV cache and error accumulation over time. BIFE proposes a semantic sparse KV cache for retrieval-based long-range conditioning and a Block Forcing training strategy to enforce cross-block consistency. The authors also introduce InterVBench, a minute-long video benchmark with fine-grained block-level annotations and Video Drift Error metrics. Experiments show BIFE achieves state-of-the-art performance with a 22.2% improvement on VDE-Subject and 19.4% on VDE-Clarity over baselines.
Source

Key quotes
· 5 pulledLong video generation is a critical step toward building realistic world models, requiring both high visual fidelity and long-range interaction consistency.
Recent autoregressive diffusion models enable long-horizon generation through KV cache reuse, yet suffer from two fundamental challenges: failure to preserve long-range interactions due to sliding-window KV cache and error accumulation that progressively degrades generation quality over time.
To address these issues, we propose BIFE, a framework that introduces a semantic sparse KV cache for retrieval-based long-range conditioning and a Block Forcing training strategy to enforce cross-block consistency.
Together, these designs preserve historical interactions while mitigating drift, enabling stable and coherent minute-long video generation.
Extensive experiments on InterVBench and VBench-Long demonstrate that BIFE achieves state-of-the-art performance, including a 22.2% improvement on VDE-Subject and a 19.4% improvement on VDE-Clarity over baselines.
You might also wanna read

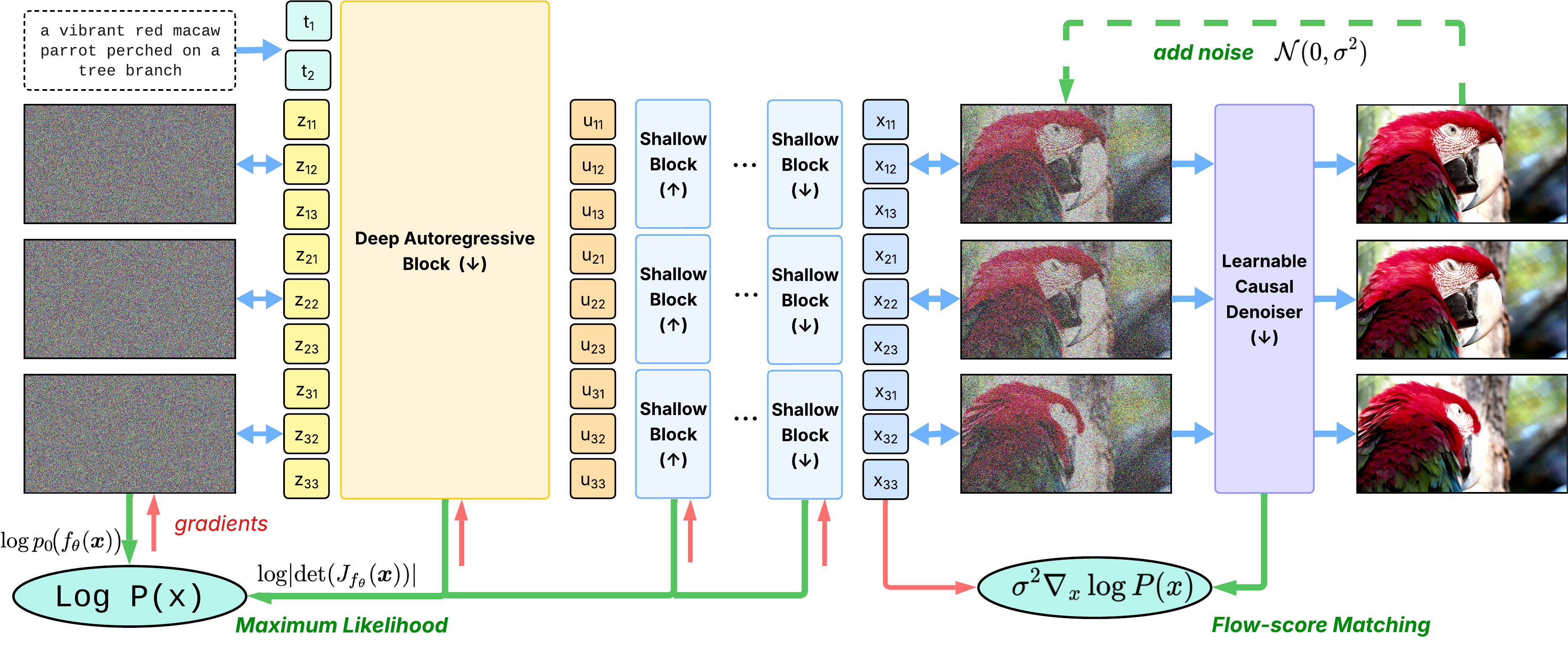
STARFlow-V: Normalizing Flow-Based Video Generation Model with End-to-End Learning
STARFlow-V is a normalizing flow-based video generation model that offers end-to-end learning, robust causal prediction, and native likeliho

Fast-dLLM: Training-Free Acceleration Method for Diffusion Language Models Using KV Cache and Parallel Decoding
Researchers introduce Fast-dLLM, a training-free acceleration method for diffusion-based large language models that addresses their slower i

Image Diffusion Models Enable Zero-Shot Video Object Tracking Through Temporal Propagation
Researchers demonstrate that image diffusion models, originally designed for image generation, contain rich semantic structures that can be
TurboDiffusion: Video Diffusion Model Acceleration Framework Achieves 100-200x Speedup
TurboDiffusion is a video generation acceleration framework that can speed up end-to-end diffusion generation by 100-200 times on a single R
 github.com·6mo ago
github.com·6mo ago
Helios: A 14B Parameter Real-Time Video Generation Model for Minute-Scale Content
Helios is a 14B parameter video generation model that achieves real-time performance at 19.5 FPS on a single NVIDIA H100 GPU while supportin
 alphaxiv.org·3mo ago
alphaxiv.org·3mo ago
StreamingVLM: Real-Time Vision-Language Model for Infinite Video Stream Processing
StreamingVLM is a new vision-language model designed for real-time understanding of infinite video streams, addressing the computational cha
Comments
Sign in to join the conversation.
No comments yet. Be the first.