Image Diffusion Models Enable Zero-Shot Video Object Tracking Through Temporal Propagation
By
50kIters
Warm and crisp on the edges. A bagel with a bit of bite.
Summary
Researchers demonstrate that image diffusion models, originally designed for image generation, contain rich semantic structures that can be repurposed for video analysis. By reinterpreting self-attention maps as semantic label propagation kernels, the models can establish pixel-level correspondences between image regions. When extended across video frames, this creates a temporal propagation kernel enabling zero-shot object tracking via segmentation. The paper introduces DRIFT, a framework that leverages pretrained image diffusion models with SAM-guided mask refinement, achieving state-of-the-art zero-shot performance on video object segmentation benchmarks.
Key quotes
· 3 pulledImage diffusion models, though originally developed for image generation, implicitly capture rich semantic structures that enable various recognition and localization tasks beyond synthesis.
Extending this mechanism across frames yields a temporal propagation kernel that enables zero-shot object tracking via segmentation in videos.
We introduce DRIFT, a framework for object tracking in videos leveraging a pretrained image diffusion model with SAM-guided mask refinement, achieving state-of-the-art zero-shot performance on standard video object segmentation benchmarks.
You might also wanna read

Apple to present 14 AI research papers at CVPR conference in Denver ahead of WWDC
Apple will present 14 AI research papers at the 2026 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) in Denver next we
 appleinsider.com·3d ago
appleinsider.com·3d ago
LoGeR: Hybrid Memory System Enables Dense 3D Reconstruction from Long Videos
LoGeR (Long-Context Geometric Reconstruction with Hybrid Memory) is a novel AI system developed by Google DeepMind and UC Berkeley researche

Apple's SHARP: Photorealistic View Synthesis from Single Images in Under a Second
Apple researchers present SHARP, a novel approach for photorealistic view synthesis from a single image. The method uses a 3D Gaussian repre
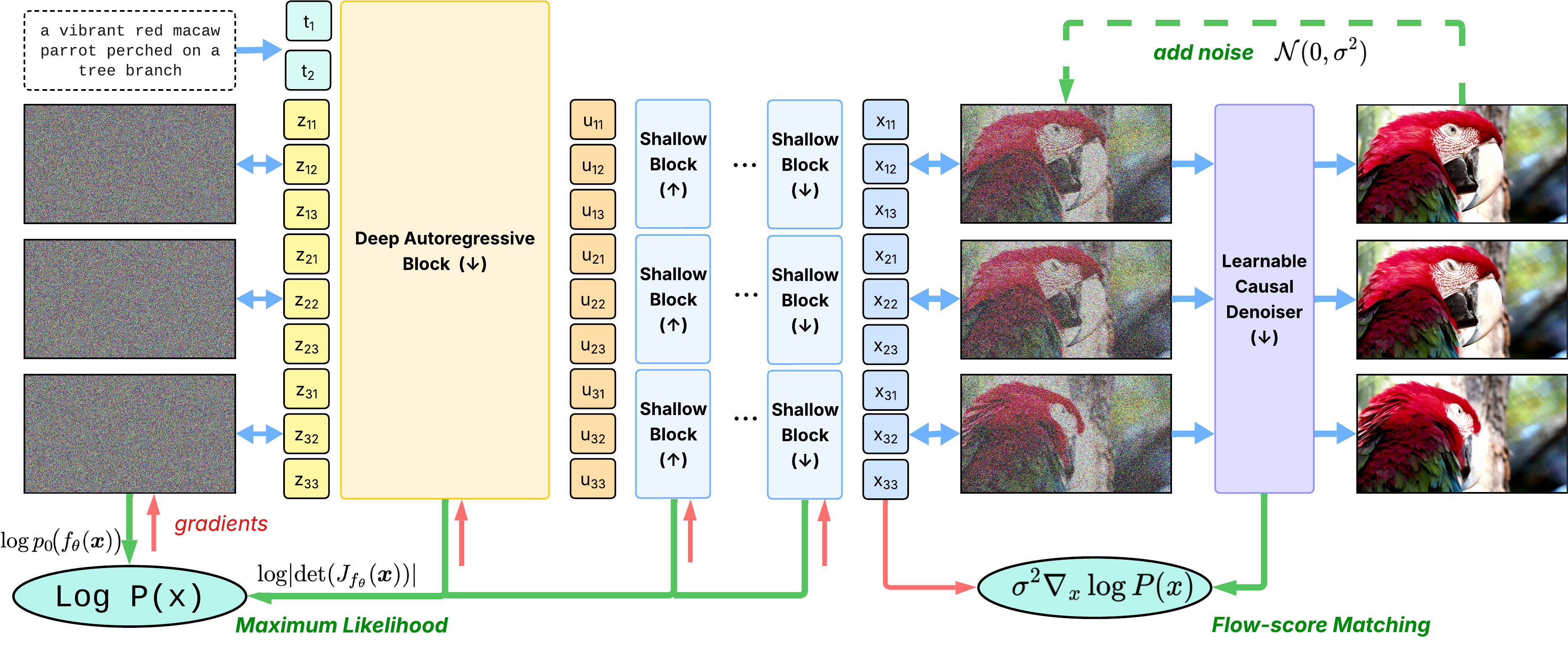
STARFlow-V: Normalizing Flow-Based Video Generation Model with End-to-End Learning
STARFlow-V is a normalizing flow-based video generation model that offers end-to-end learning, robust causal prediction, and native likeliho

Spatial Intelligence: The Next Frontier in AI Development Beyond Language Models
The article discusses the evolution of AI from basic computation to spatial intelligence, tracing the author's journey from creating ImageNe
 drfeifei.substack.com·6mo ago
drfeifei.substack.com·6mo ago
Video Models Demonstrate Zero-Shot Learning Capabilities Similar to Large Language Models
The article discusses how video models like Veo 3 are demonstrating zero-shot learning capabilities similar to Large Language Models (LLMs),
 video-zero-shot.github.io·8mo ago
video-zero-shot.github.io·8mo ago