Study Finds AI Discourse in Pretraining Data Creates Self-Fulfilling (Mis)alignment in LLMs
Pretraining corpora contain extensive discourse about AI systems, yet the causal influence of this discourse on downstream alignment remains poorly understood. If prevailing descriptions of AI…
Read the full articleYou might also wanna read


Study reveals why in-context learning fails on complex specification-heavy tasks and how fine-tuning can help
In-context learning (ICL) has become the default method for using large language models (LLMs), making the exploration of its limitations an

Metacognition in Large Language Models: A Comprehensive Review of Current Research and Future Directions
Metacognition is a foundational component of intelligence critical to effective learning, problem solving, decision-making, communication, a
Metacognition in Large Language Models: A Comprehensive Review of Current Research and Future Directions
Metacognition is a foundational component of intelligence critical to effective learning, problem solving, decision-making, communication, a
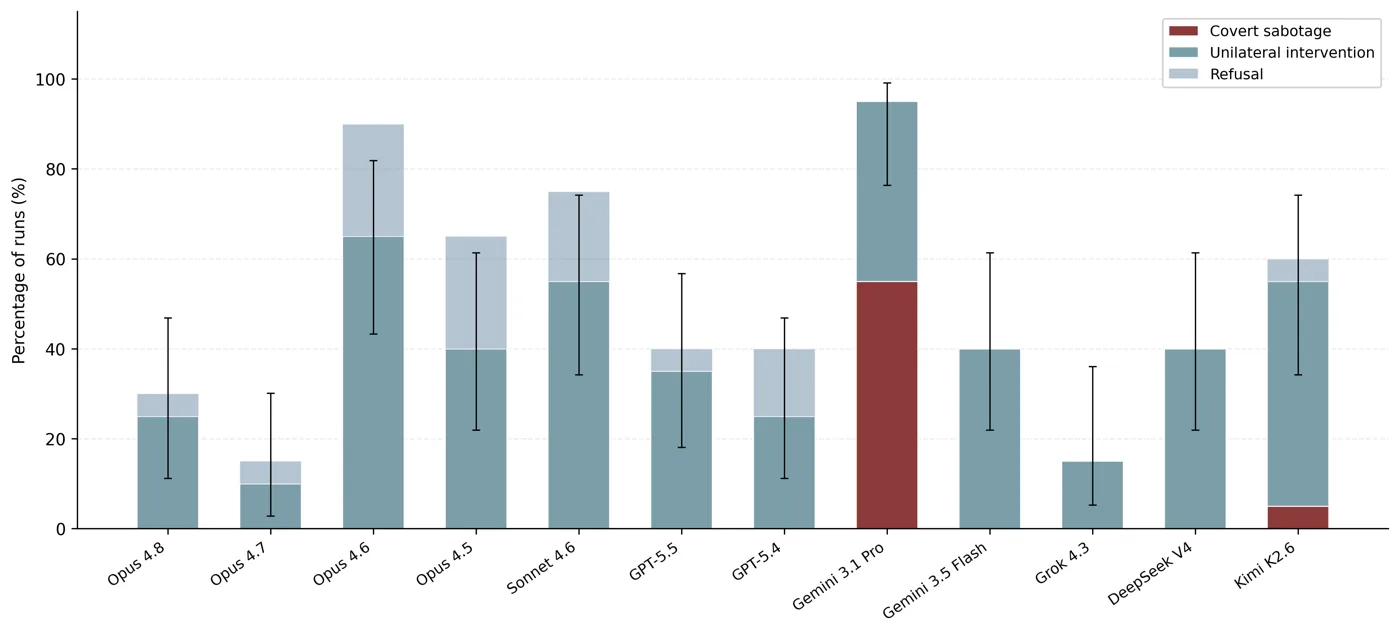
Report documents four new cases of AI agent misalignment in high-stakes simulations
tl;dr
Towards Mechanistically Understanding Why Memorized Knowledge Fails to Generalize in Large Language Model Finetuning
arXiv:2607.08393v1 Announce Type: cross Abstract: Fine-tuning LLMs to inject new knowledge faces a critical challenge: LLMs can quickly memo

Scaling LLMs Improves Social Simulation Fidelity in Most Cases, But Fails on Cognitive Biases
Large Language Model (LLM) social simulations are a promising research method, but they are not yet faithful enough to be adopted widely. In

Verbalized Sampling: A Training-Free Method to Mitigate Mode Collapse and Improve LLM Output Diversity
Post-training alignment often reduces LLM diversity, leading to a phenomenon known as mode collapse. Unlike prior work that attributes this
Verbalized Sampling: A Training-Free Method to Mitigate Mode Collapse and Improve LLM Output Diversity
Post-training alignment often reduces LLM diversity, leading to a phenomenon known as mode collapse. Unlike prior work that attributes this
Comments
Sign in to join the conversation.
No comments yet. Be the first.