Alibaba's Qwen3-VL AI Model Demonstrates Advanced Video Analysis Capabilities
A few months after launching Qwen3-VL, Alibaba has released a detailed technical report on the open multimodal model. The data shows the system excels at image-based math tasks and can analyze hours…
Read the full articleYou might also wanna read


Alibaba's Qwen3.7-Plus combines visual AI with autonomous agent capabilities for coding and app navigation
Alibaba's Qwen team has released Qwen3.7-Plus, a multimodal agent model that combines visual perception, GUI operation, and coding in a sing
 the-decoder.com·1mo ago
the-decoder.com·1mo ago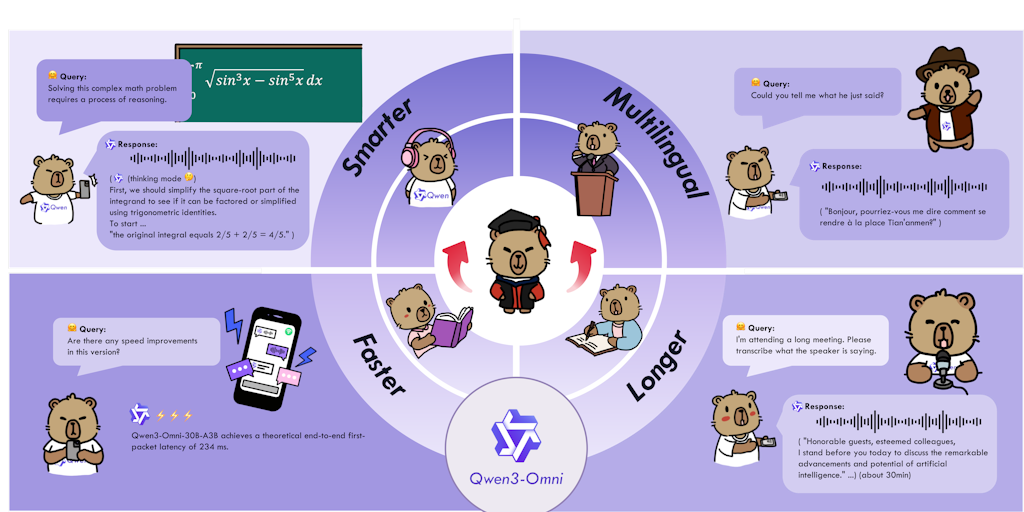
Alibaba Cloud Launches Qwen3-Omni: Native Multimodal AI Model with Real-Time Speech Generation
Qwen3 is the large language model series developed by Qwen team, Alibaba Cloud. - QwenLM/Qwen3
 Product Hunt·2mo ago
Product Hunt·2mo agoQwen 3.5 Review: Alibaba's Native Multimodal Agent Family — 397B MoE, 262K Context, Apache 2.0
Qwen 3.5 (February–March 2026) is Alibaba's most architecturally ambitious model family: nine sizes from 0.8B to 397B, hybrid linear+sparse

Qwen3.6 Models: How to Run Alibaba's New Multimodal AI Locally with Unsloth
Run the new Qwen3.6-27B and 35B-A3B models locally!
 unsloth.ai·7d ago
unsloth.ai·7d agoQwen3.6 Models: How to Run Alibaba's New Multimodal AI Locally with Unsloth
Run the new Qwen3.6-27B and 35B-A3B models locally!
unsloth.ai·7d ago
Qwen-VL: Multimodal AI Model for Visual Understanding and Reasoning
QwQ-Max-Preview from Qwen is a powerful new LLM excelling in reasoning, math, coding, and agent tasks. Features a "thinking mode" for comple
Product Hunt·10mo agoAlibaba Qwen 3 — Hybrid Thinking, Apache 2.0, and the Best Open-Weight Model Family in 2025
Alibaba's Qwen 3 (April 28, 2025) redefined what open-weight AI can do: frontier-class performance, switchable 'thinking' mode, 100+ languag
Comments
Sign in to join the conversation.
No comments yet. Be the first.