Startup Subquadratic claims faster, cheaper LLM that processes 12x more text
By
Will Douglas Heaven
Summary
Subquadratic, a startup, claims to have developed a new LLM called SubQ that is faster, cheaper, and more energy-efficient than existing models. The company says SubQ can process up to 12 times more text at once than most models, enabling data-heavy tasks like analyzing hundreds of documents or entire code bases, while matching the performance of leading models from Google DeepMind, OpenAI, and others. However, skepticism remains as the company has only recently shared more details about its claims.
Source

 bskyStartup Subquadratic claims faster, cheaper LLM that processes 12x more texttechnologyreview.com
bskyStartup Subquadratic claims faster, cheaper LLM that processes 12x more texttechnologyreview.comKey quotes
· 3 pulledSubquadratic claims it has developed a new kind of LLM, called SubQ, that is faster and cheaper and uses a lot less energy than any other model on the market.
SubQ is able to process up to 12 times as much text at once than most other models, allowing it to carry out a range of data-heavy tasks.
Subquadratic has now shared more details about its new model. But some are still skeptical.
You might also wanna read


Subquadratic Launches SubQ 1.1 Small LLM with Competitive Benchmark Performance
Subquadratic introduces SubQ 1.1 Small, a new LLM that balances long-context optimization with general reasoning. The model achieves strong
 subq.ai·7d ago
subq.ai·7d ago
Subquadratic launches AI architecture with 12-million-token context window, outperforming GPT-5.5 on retrieval benchmarks
Subquadratic has launched a new AI architecture featuring a 12-million-token context window, shattering the current million-token standard s
 The New Stack·1mo ago
The New Stack·1mo ago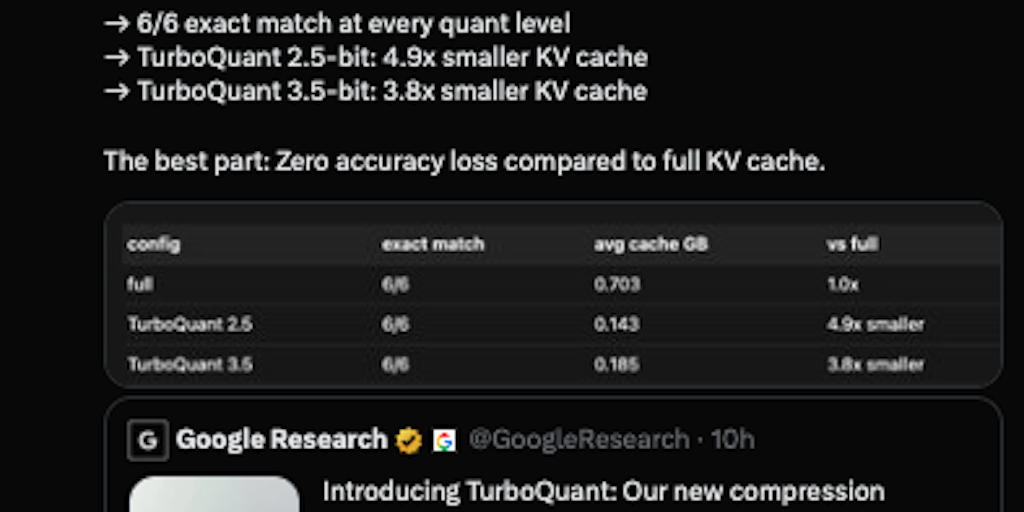
Google Introduces TurboQuant: Advanced LLM Compression Algorithm for Efficient AI Model Deployment
Google has developed TurboQuant, a new LLM compression algorithm that uses advanced theoretically grounded quantization techniques to enable
 Product Hunt·3mo ago
Product Hunt·3mo ago
Roofline Model for Estimating Speculative Decoding Speedup in LLM Inference
This article presents a roofline model for estimating speedup ratios from speculative decoding in large language model (LLM) inference. It a
 modal.com·1d ago
modal.com·1d ago
Optimizing LLM Inference by Combining NVIDIA DGX Spark and Apple Mac Studio Architectures
The article explores combining NVIDIA DGX Spark AI supercomputers with Apple Mac Studio systems to optimize large language model (LLM) infer
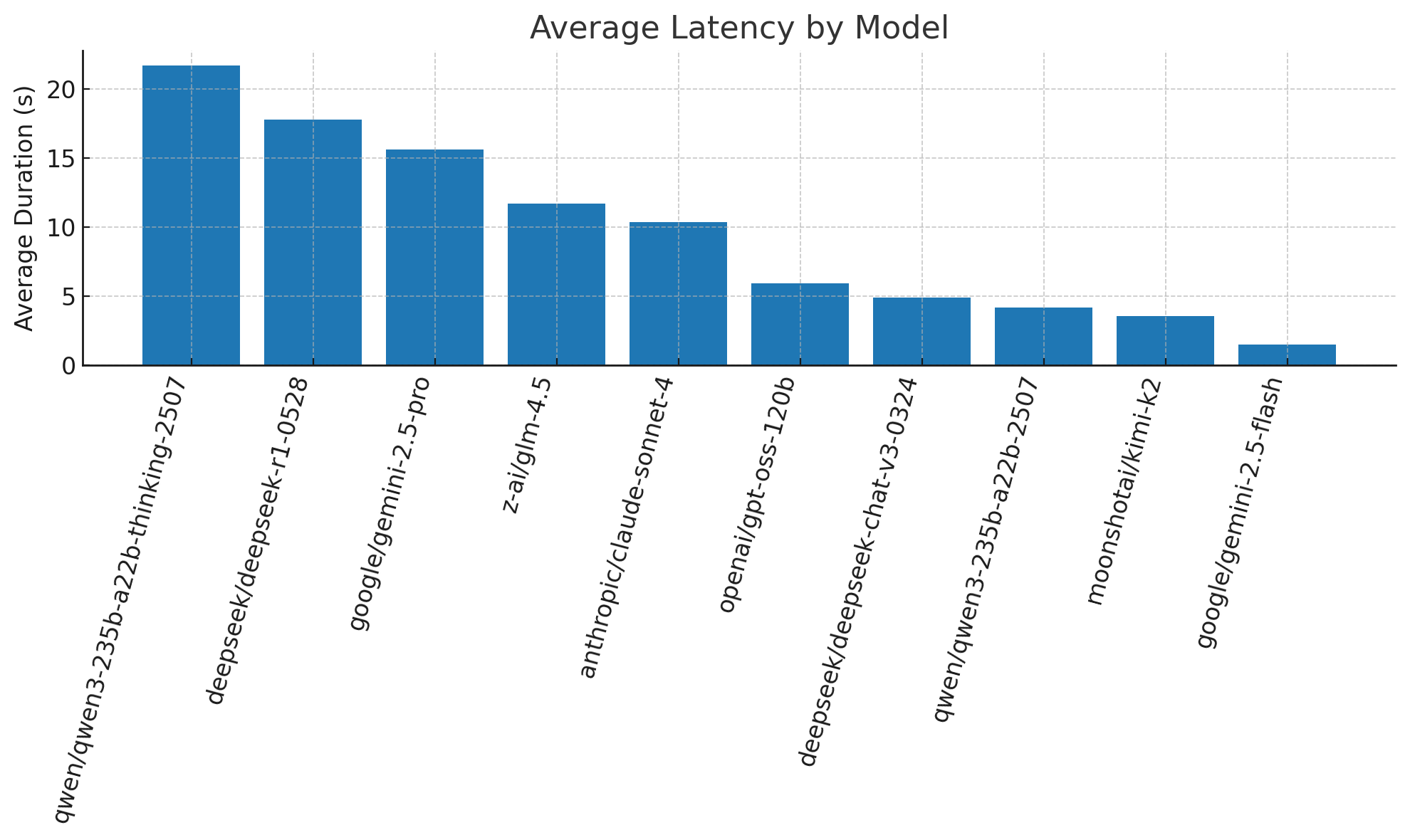
Practical Evaluation of Large Language Models for Everyday Programming and Technical Tasks
The author conducted a personal evaluation of large language models (LLMs) for practical, everyday use cases rather than academic benchmarks
 darkcoding.net·10mo ago
darkcoding.net·10mo agoComments
Sign in to join the conversation.
No comments yet. Be the first.