Dynamic GPU Capacity Controller Reallocates Idle Production GPUs to Research During Off-Peak Hours
By
Runway Team
Summary
The article describes how the authors built a capacity controller that dynamically reallocates GPUs between production inference workloads and research tasks based on daily demand cycles. Using queueing theory, they optimized GPU allocation so that production tracks demand without over-provisioning, freeing up more GPUs for research during off-peak overnight hours while reducing queue wait times throughout the day. The system builds on their previous work using Kueue to lend idle GPUs across research initiatives, now extending the concept to reclaim production GPUs for research during low-demand periods and return them before the morning peak.
Source

Key quotes
· 3 pulledWe built a capacity controller that reallocates GPUs between production and research so production tracks demand without over-provisioning.
Using queueing theory we optimized allocations, leading to more GPUs for research overnight and shorter queue waits all day.
Here we focus on reclaiming production GPUs for research during off-peak hours, then returning them before the morning peak.
You might also wanna read


South Korea's GPU Race: Why AI Competitiveness Depends on Utilization, Not Just Hardware
South Korea is aggressively expanding its AI GPU infrastructure as a national strategic priority, but the article raises critical questions
 koreatechdesk.com·26d ago
koreatechdesk.com·26d ago
OmniPilot: An LLM Inference Advisor for Optimizing GPU Cluster Configuration Selection
OmniPilot is an uncertainty-aware LLM inference advisor designed for heterogeneous GPU clusters. It helps users and operators select optimal
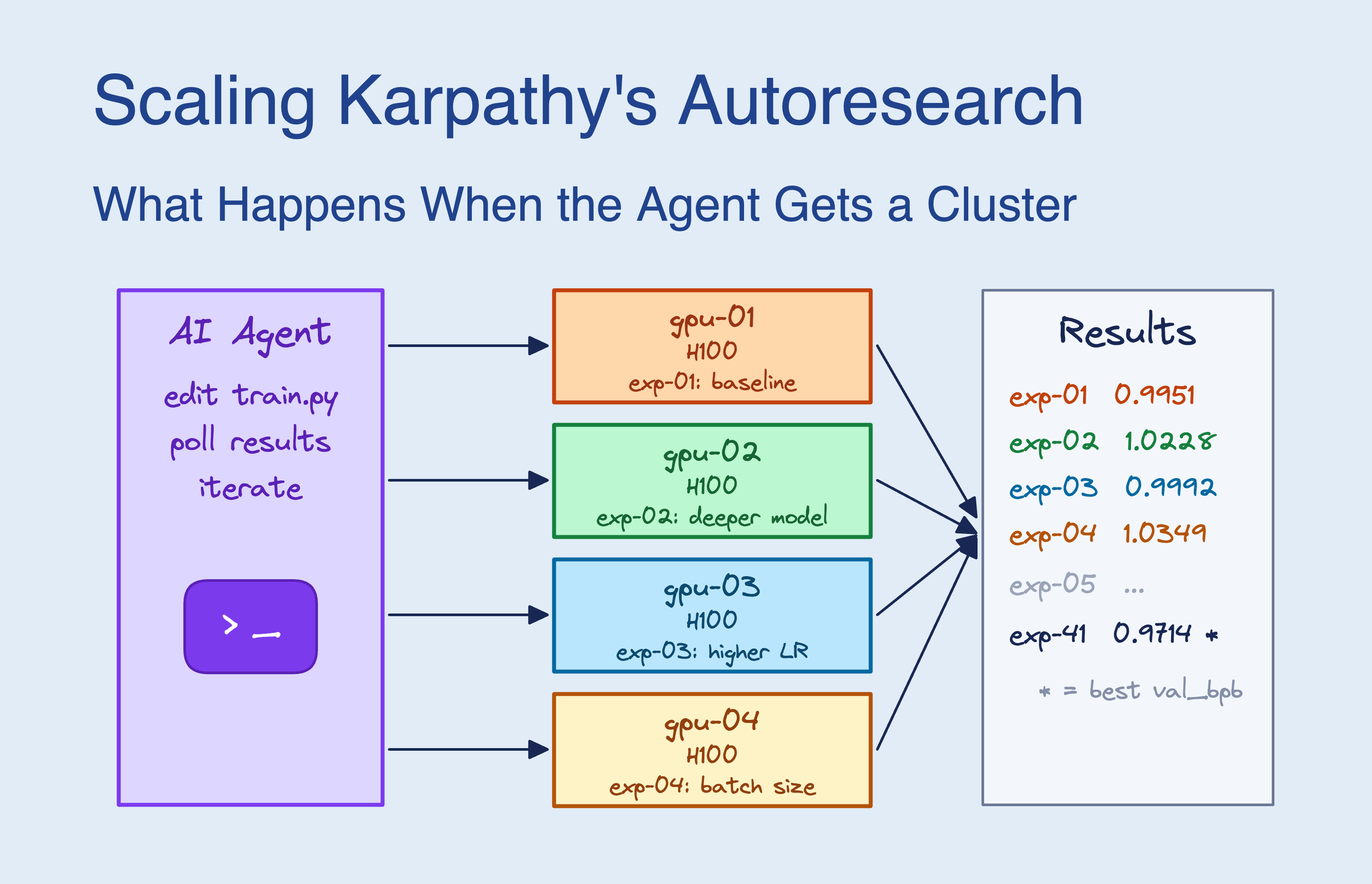
Scaling Karpathy's Autoresearch: Parallel GPU Processing Enables New AI Experimentation Strategies
The article describes an experiment where researchers scaled Andrej Karpathy's autoresearch system by giving it access to 16 GPUs on a Kuber
 blog.skypilot.co·3mo ago
blog.skypilot.co·3mo ago
Rotary GPU: Enabling Large Mixture-of-Experts Models on Consumer Laptop GPUs with Limited Memory
This paper presents Rotary GPU, an exploratory approach to running large Mixture-of-Experts (MoE) language models on consumer-grade hardware

AI-Driven Approach for Portable GPU Kernels in High-Performance Computing
This academic paper from North Carolina State University researchers presents an approach to leveraging AI ecosystems for creating portable
 hgpu.org·17d ago
hgpu.org·17d agoCompute Resource Management Simulation: Forecasting Demand and Allocating Resources
The article presents a simulation scenario where the reader takes on the role of Dario, tasked with managing compute resource allocation in
Comments
Sign in to join the conversation.
No comments yet. Be the first.