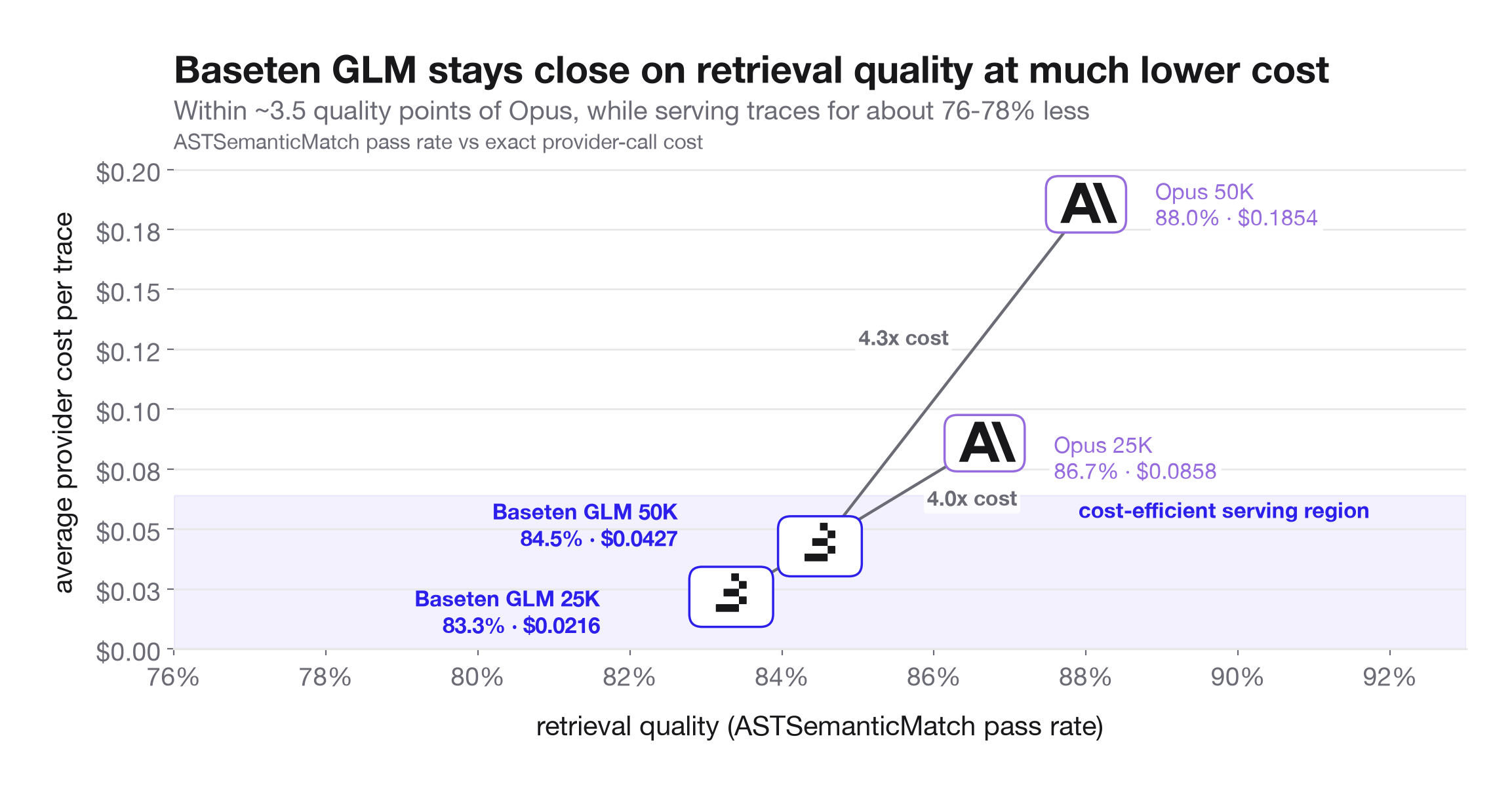
Benchmarking GLM-5.2 vs Opus 4.8: Long-context retrieval performance for coding agents
This article benchmarks GLM-5.2 (an open-source model from Z.ai) against Anthropic's Opus 4.8 for long-context retrieval in coding agent use cases. Using a Braintrust-native evaluation framework, the authors test both models on exact retrieval from long contexts, comparing perfor