ZSE: Ultra Memory-Efficient LLM Inference Engine for Running Large Models on Consumer GPUs
By
zyoralabs
Pulled from the oven just right. Trustworthy, fact-dense, deeply satisfying.
Summary
ZSE (Z Server Engine) is an ultra memory-efficient LLM inference engine with native INT4 CUDA kernels that enables running large language models on consumer-grade GPUs. It allows running 32B models on 24GB GPUs and 7B models on 8GB GPUs, featuring fast cold starts and single-file deployment. The latest version v1.4.1 adds Model Hub and Pull Commands functionality, and it supports training 7B models on 8GB GPUs and 70B models on 48GB GPUs. The article includes verified benchmarks showing performance metrics for various models like Qwen 7B and Qwen 14B on H200 GPUs.
Key quotes
· 5 pulledUltra memory-efficient LLM inference engine with native INT4 CUDA kernels.
Run 32B models on 24GB GPUs. Run 7B models on 8GB GPUs. Fast cold starts, single-file deployment.
Train 7B models on 8GB GPUs. Train 70B models on 48GB GPUs.
ZSE Custom Kernel (Default)
Qwen 7B: 5.57 GB file size, 5.67 GB VRAM, 37.2 tok/s speed, 5.7s cold start on H200 GPU
You might also wanna read

Guide to Calculating GPU Memory for Self-Hosted LLM Inference
The article provides a guide on calculating GPU memory requirements and managing concurrent requests for self-hosted large language model (L
 Product Hunt·9mo ago
Product Hunt·9mo ago
Zibra AI Launches GPU-Native Data Orchestration Platform for Spatial AI Training
Zibra AI introduces a GPU-native data orchestration platform designed to solve I/O bottlenecks in spatial and physical AI training. The plat
 Product Hunt·1mo ago
Product Hunt·1mo ago
RTP-LLM: Alibaba's High-Performance Inference Engine for Large Language Model Deployment
This paper presents RTP-LLM, a high-performance inference engine developed by Alibaba for industrial-scale deployment of Large Language Mode
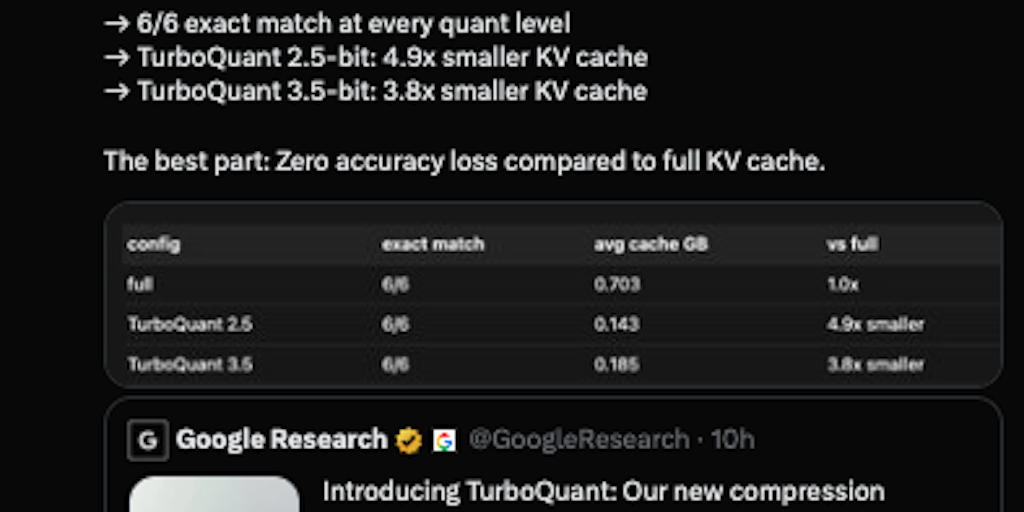
Google Introduces TurboQuant: Advanced LLM Compression Algorithm for Efficient AI Model Deployment
Google has developed TurboQuant, a new LLM compression algorithm that uses advanced theoretically grounded quantization techniques to enable
Product Hunt·2mo ago