Zero-Copy GPU Inference from WebAssembly on Apple Silicon: Direct Memory Sharing Between Wasm and GPU
A WebAssembly module's linear memory can be shared directly with the Apple Silicon GPU: no copies, no serialization, no intermediate buffers. Here's how the zero-copy chain works, what we measured…
Read the full articleYou might also wanna read

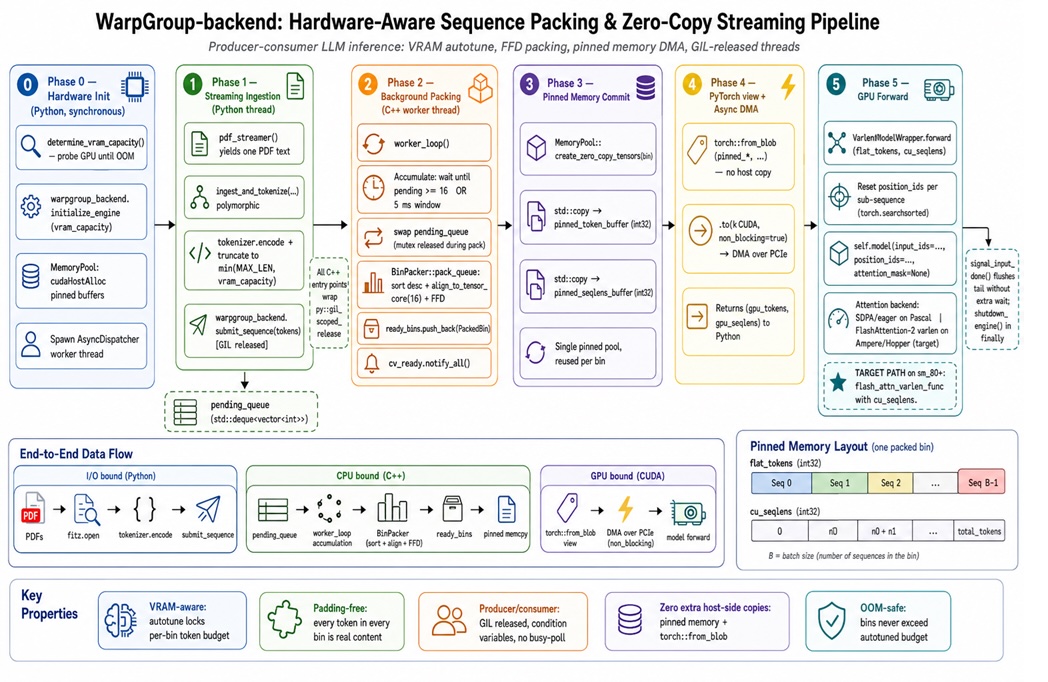
Optimizing LLM Inference: A C++ Backend for VRAM-Aware Sequence Packing
A comprehensive guide to optimizing LLM inference by eliminating padding overhead with hardware-aware sequence packing.
 towardsdatascience.com·1mo ago
towardsdatascience.com·1mo agoWhy Your M4 Max Runs LLMs Like a GPU Beast — Without a Single CUDA Core
The secret isn’t brute-force compute. It’s a memory architecture that rewrites the rules of local AI inference. Continue reading on Medium »

APEX4: Platform-Dependent W4A4 LLM Inference via Intra-SM Compute Rebalancing
W4A4 quantization promises full utilization of INT4 Tensor Cores, yet group dequantization overhead on CUDA Cores has driven existing system

LLM Inference Benchmarking - Measure What Matters
Production-grade LLM inference is a complex systems challenge, requiring deep co-designs - from hardware primitives (FLOPs, memory bandwidth

Researchers Serve 229B-Parameter MoE Model Across Five Consumer GPUs Over Public Internet
We serve MiniMax-M2.5, a 229B-parameter mixture-of-experts model, split across five consumer RTX 5090s in five European countries. The stage
 doi.org·13d ago
doi.org·13d agoMesh LLM Needs Failure Planning, Not Just Free GPUs, Experts Warn
Mesh LLM, an OpenAI-compatible API capable of running locally or distributing model layers across multiple machines, gained significant trac
Comments
Sign in to join the conversation.
No comments yet. Be the first.