Workers AI - Deepgram and Leonardo partner models now available on Workers AI
10mo ago
Source
CloudflareWorkers AI - Deepgram and Leonardo partner models now available on Workers AIcloudflare.comNew state-of-the-art models have landed on Workers AI! This time, we're introducing new partner models trained by our friends at Deepgram and Leonardo , hosted on Workers AI infrastructure. As well, we're introuding a new turn detection model that enables you to detect when someone is done speaking — useful for building voice agents! Read the blog for more details and check out some of the new models on our platform: @cf/deepgram/aura-1 is a text-to-speech model that allows you to input text and have it come to life in a customizable voice @cf/deepgram/nova-3 is speech-to-text model that transcribes multilingual audio at a blazingly fast speed @cf/pipecat-ai/smart-turn-v2 helps you detect when someone is done speaking @cf/leonardo/lucid-origin is a text-to-image model that generates images with sharp graphic design, stunning full-HD renders, or highly specific creative direction @cf/leonardo/phoenix-1.0 is a text-to-image model with exceptional prompt adherence and coherent text You can filter out new partner models with the Partner capability on our Models page. As well, we're introducing WebSocket support for some of our audio models, which you can filter though the Realtime capability on our Models page. WebSockets allows you to create a bi-directional connection to our inference server with low latency — perfect for those that are building voice agents. An example python snippet on how to use WebSockets with our new Aura model: import json import os import asyncio import websockets uri = f"wss://api.cloudflare.com/client/v4/accounts/{ACCOUNT_ID}/ai/run/@cf/deepgram/aura-1" input = [ "Line one, out of three lines that will be provided to the aura model.", "Line two, out of three lines that will be provided to the aura model.", "Line three, out of three lines that will be provided to the aura model. This is a last line.", ] async def text_to_speech(): async with websockets.connect(uri, additional_headers={"Authorization": os.getenv("CF_TOKEN")}) as websocket: print("connection established") for line in input: print(f"sending `{line}`") await websocket.send(json.dumps({"type": "Speak", "text": line})) print("line was sent, flushing") await websocket.send(json.dumps({"type": "Flush"})) print("flushed, recving") resp = await websocket.recv() print(f"response received {resp}") if __name__ == "__main__": asyncio.run(text_to_speech())
You might also wanna read


Deepgram: Enterprise Voice AI Platform for Developers
Deepgram is an enterprise Voice AI platform designed for developers building voice-first products. It offers speech-to-text, text-to-speech,
 Product Hunt·1y ago
Product Hunt·1y agoI built a voice AI that has memory, executes real tools, and has a body made of particles
v.redd.it·1mo ago
Building a Multi-Channel AI Appointment Agent with AgenDuet, Bedrock Nova Sonic, and OpenClaw
A technical guide presents an architectural blueprint for "Claudia," an inbound clinic appointment assistant that solves voice AI latency is
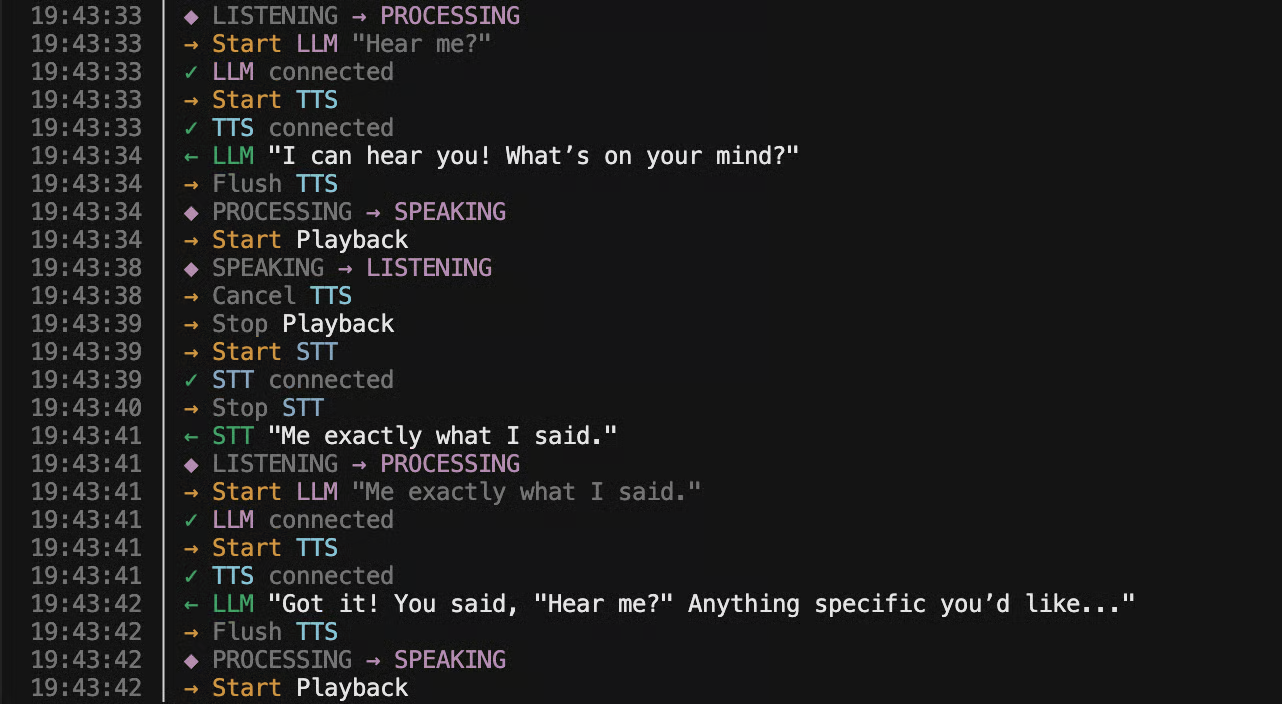
Building a Sub-500ms Latency Voice Agent: Technical Architecture and Implementation
Nick Tikhonov shares his technical journey building a sub-500ms latency voice agent from scratch, detailing the challenges of achieving real
 ntik.me·4mo ago
ntik.me·4mo ago
Google launches Gemini 3.1 Flash TTS with expressive AI speech capabilities
Google has released Gemini 3.1 Flash TTS, a next-generation text-to-speech model that delivers highly expressive, natural-sounding AI speech
 blog.google·18d ago
blog.google·18d ago
VoiceAI: A Developer's Learning Path for Building Real-Time Voice Agents
A curated, developer-friendly learning path for building real-time voice AI agents, covering the full stack from speech-to-text foundations
 GitHub·2mo ago
GitHub·2mo ago
Comments
Sign in to join the conversation.
No comments yet. Be the first.