We stress tested many frontier AI models for multimodal medical reasoning (including GPT-5, Claude 3.5, Gemini 2.5 Pro). They’re not ready. Faulty reasoning, use of inappropriate shortcuts, hallucinat
8d ago· 1 min readNews
Source
 Twitter / XWe stress tested many frontier AI models for multimodal medical reasoning (including GPT-5, Claude 3.5, Gemini 2.5 Pro). They’re not ready. Faulty reasoning, use of inappropriate shortcuts, hallucinatnature.com
Twitter / XWe stress tested many frontier AI models for multimodal medical reasoning (including GPT-5, Claude 3.5, Gemini 2.5 Pro). They’re not ready. Faulty reasoning, use of inappropriate shortcuts, hallucinatnature.comWe stress tested many frontier AI models for multimodal medical reasoning (including GPT-5, Claude 3.5, Gemini 2.5 Pro). They’re not ready. Faulty reasoning, use of inappropriate shortcuts, hallucinations. Published today @NatureMedicine
You might also wanna read


Study Finds Frontier AI Models Disagree on Two-Thirds of Basic Fact-Check Claims
A new study by researcher Kosta Jordanov at Lenz Research tested five frontier AI models (GPT-5.4, Claude Opus 4.7, Gemini 3 Pro, Gemini 3 P
 decrypt.co·1mo ago
decrypt.co·1mo ago
OpenAI Research Explains Why Language Models Hallucinate and How to Improve Reliability
OpenAI's research paper explains that language models hallucinate because standard training and evaluation procedures reward guessing over a
 openai.com·10mo ago
openai.com·10mo ago
ClinHallu: A New Benchmark for Diagnosing Hallucination Sources in Medical AI Reasoning
This paper introduces ClinHallu, a benchmark designed to diagnose stage-wise hallucinations in medical multimodal large language models (MLL
GPT-5 underperforms in medical language understanding [pdf]
fertrevino.com·10mo ago

Examining the Limitations of Transformer Models and the Gap to Human-Level AI
The article presents a skeptical perspective on claims about imminent Artificial General Intelligence (AGI), arguing that current transforme
dlants.me·4mo ago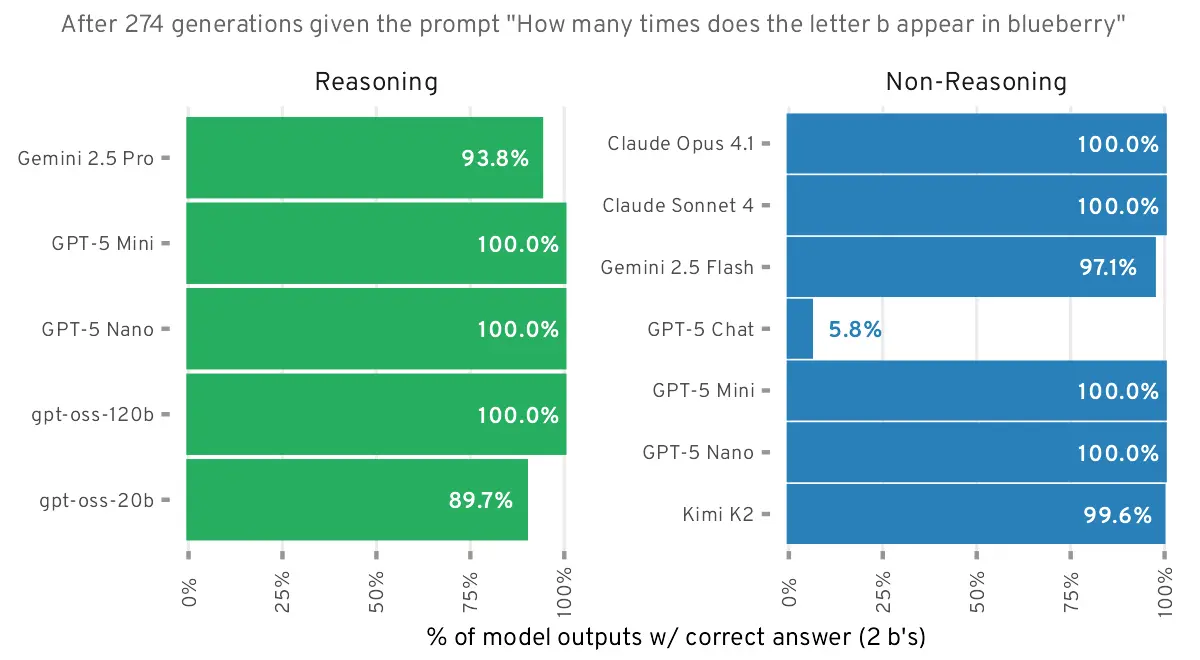
GPT-5 fails basic reasoning test: Can't count the 'b's in "blueberry"
The article discusses the release of GPT-5 by OpenAI and the widespread disappointment in the AI community and beyond regarding its performa
 minimaxir.com·10mo ago
minimaxir.com·10mo ago
Comments
Sign in to join the conversation.
No comments yet. Be the first.