VideoWeaver: A Benchmark for Evaluating AI Agent Skills in Long Video Generation
By
[Submitted on 6 Jun 2026]
Summary
VideoWeaver is a new agent harness and benchmark designed to evaluate and improve AI agents' ability to generate long videos from a single instruction. Unlike traditional video agents with handcrafted pipelines, VideoWeaver allows agent frameworks (like Claude Code, Codex, and OpenClaw) to build and refine their own workflows by composing foundation skills. The benchmark includes 16 task categories and 285 test cases with multimodal references. It introduces an "agent-as-judge" that evaluates both the execution trace and final video, and a skill evolution algorithm that refines and merges agent skills. Key findings show that explicit composition skills improve generation, skill evolution boosts output quality, and the agent-as-judge aligns well with human judgments.
Source

Key quotes
· 4 pulledWe introduce VideoWeaver, an agent harness and benchmark that evaluates and evolves skills for long video generation, where an agent turns a single instruction into a long video by composing foundation skills into its own workflow rather than following a predefined pipeline.
Because errors can arise at any stage and not just in the final video, we propose an agent-as-judge that inspects both the execution trace and the final video, grounding its scores in evidence such as metadata and intermediate files.
Across multiple frameworks and models, we find that an explicit composition skill improves the generation process over using foundation skills alone, that skill evolution further improves output quality, and that performance varies notably across harness and model choices.
The proposed agent-as-judge also aligns well with human judgments, especially on process metrics.
You might also wanna read


SkillsBench: A Benchmark for Evaluating AI Agent Skills Across Diverse Tasks
SkillsBench is a new benchmark for evaluating how well AI agent skills work across diverse tasks. The benchmark includes 86 tasks across 11
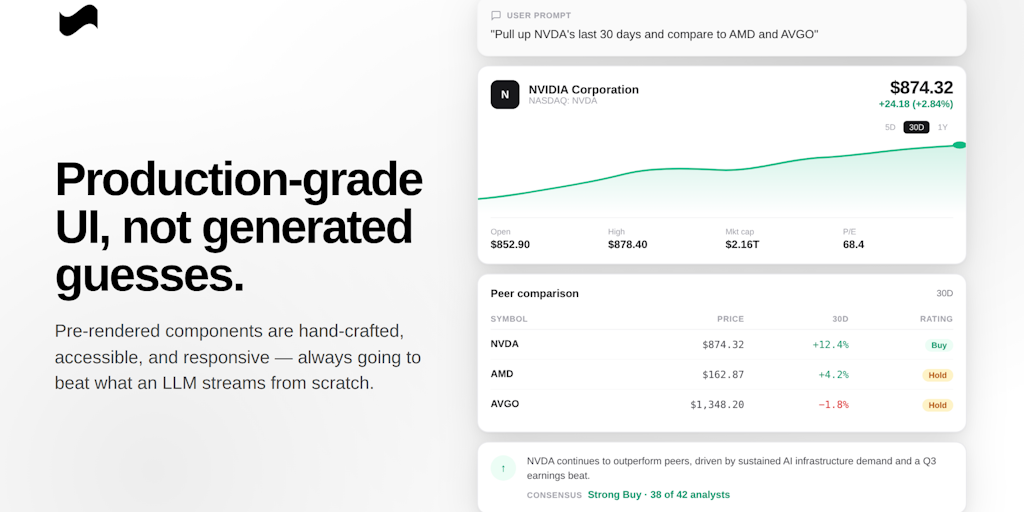
Montage: A UI Agentic Framework That Reduces Token Usage and Speeds Up AI Agent Rendering
Montage is a UI agentic framework that optimizes AI agent UI rendering by having agents emit a small intent schema, which is then compiled s
 Product Hunt·1mo ago
Product Hunt·1mo ago
AI Model Benchmark: The Evolution from Zero-Shot to Agentic Approaches for Creative Tasks
The article discusses Simon Willison's informal benchmark test for AI models: generating an SVG image of a pelican riding a bicycle. This se
 robert-glaser.de·7mo ago
robert-glaser.de·7mo ago
Skill-MAS: A Meta-Skill Approach to Improving Multi-Agent Systems Without Retraining
Skill-MAS proposes a novel approach to LLM-based automatic Multi-Agent Systems (MAS) generation that bridges the gap between inference-time
Skill-MAS: A Meta-Skill Approach to Improving Multi-Agent Systems Without Retraining
Skill-MAS proposes a novel approach to LLM-based automatic Multi-Agent Systems (MAS) generation that bridges the gap between inference-time

Benchmark Test for AI Coding Agents' Web Content Reading Capabilities
The article introduces a benchmark test called "Agent Reading Test" designed to evaluate how well AI coding agents (like Claude Code, Cursor
Web Bench: A Comprehensive Benchmark for AI Browser Agent Performance
Web Bench is a new benchmark platform designed to evaluate and compare AI browser agents' performance in web navigation tasks. It provides c
Product Hunt·1y ago
Comments
Sign in to join the conversation.
No comments yet. Be the first.