VideoMLA: Low-Rank Latent KV Cache Reduces Memory by 92.7% for Minute-Scale Video Diffusion
By
[Submitted on 28 May 2026]
Crispy enough to crunch, soft enough to enjoy. A good bake.
Summary
This paper introduces VideoMLA, the first application of Multi-Head Latent Attention (MLA) to video diffusion models. It replaces per-head key-value caches with a shared low-rank content latent and decoupled 3D-RoPE positional key, reducing per-token KV memory by 92.7% per cached layer. Despite video attention not being inherently low-rank (contrary to assumptions in language models), VideoMLA maintains quality at high compression ratios. The bottleneck itself determines effective rank rather than the pretrained spectrum. VideoMLA matches short-horizon baselines, achieves best long-horizon scores on VBench, and improves throughput by 1.23x on a single B200 GPU.
Key quotes
· 4 pulledVideoMLA replaces per-head keys and values with a shared low-rank content latent and a shared decoupled 3D-RoPE positional key, reducing per-token KV memory by 92.7% at every cached layer.
We further investigate why MLA succeeds in video diffusion even though the spectral assumption often used to motivate it in language models does not hold: pretrained video attention is not low-rank.
The MLA bottleneck, rather than the pretrained spectrum, determines the effective rank: both spectral and random initialization occupy nearly the full rank budget from initialization, and training preserves this budget while adapting within it.
On VBench, VideoMLA matches short-horizon streaming video diffusion baselines, achieves the best overall score at long horizons among evaluated methods, and improves throughput by 1.23x on a single B200.
You might also wanna read


StreamingVLM: Real-Time Vision-Language Model for Infinite Video Stream Processing
StreamingVLM is a new vision-language model designed for real-time understanding of infinite video streams, addressing the computational cha

Fast-dLLM: Training-Free Acceleration Method for Diffusion Language Models Using KV Cache and Parallel Decoding
Researchers introduce Fast-dLLM, a training-free acceleration method for diffusion-based large language models that addresses their slower i

Attention Matching: Fast KV Cache Compaction for Language Models
This article presents a new approach called Attention Matching for fast key-value (KV) cache compaction in language models. Traditional meth

Expected Attention: KV Cache Compression Method for Efficient LLM Inference
This research paper introduces Expected Attention, a training-free method for compressing Key-Value (KV) cache in large language models to r

δ-mem: A Compact Online Memory Mechanism for Efficient Long-Context LLM Processing
The article presents δ-mem, a lightweight memory mechanism for large language models that augments frozen full-attention backbones with a co
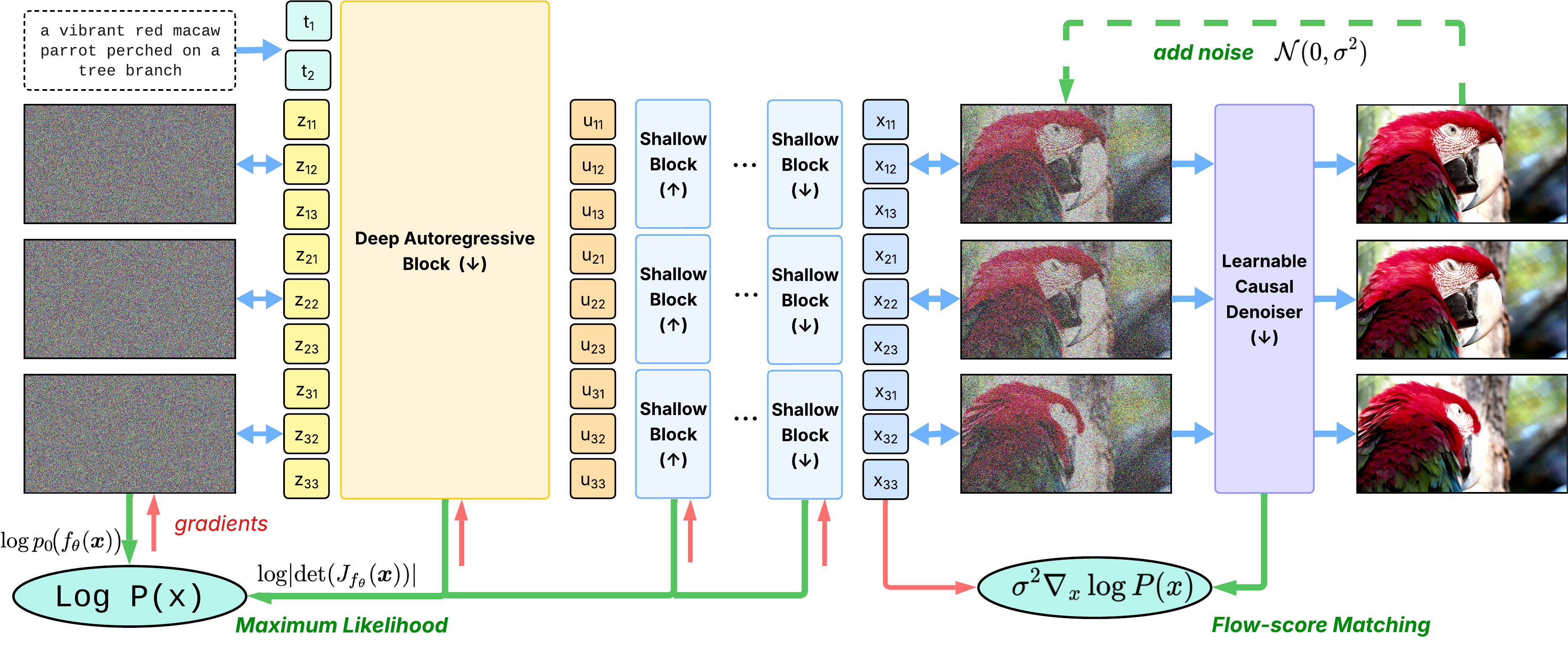
STARFlow-V: Normalizing Flow-Based Video Generation Model with End-to-End Learning
STARFlow-V is a normalizing flow-based video generation model that offers end-to-end learning, robust causal prediction, and native likeliho