Tauformer: A Topological Transformer Architecture Using Laplacian-Derived Scalar Attention
By
tuned
A five-star bake. Worth schmearing, sharing, saving.
Summary
The article discusses Tauformer, a novel topological transformer architecture that replaces traditional dot-product attention with a Laplacian-derived scalar (taumode) per token/head. The model uses a Graph Laplacian built from a domain embedding space as a persistent reference, allowing attention to be computed using distances in scalar space rather than Q·K dot products. The content provides an overview of the concept and presents initial training results from a 30M-parameter implementation, highlighting the architectural innovation and its potential implications for transformer models.
Key quotes
· 4 pulledTauformer is a topological transformer that replaces dot‑product attention with a Laplacian-derived scalar (taumode) per token/head, then attends using distances in that scalar space.
Tauformer's goal is to inject domain structure directly into attention by using a Graph Laplacian built from a domain embedding space (a 'domain memory') as a persistent reference.
Instead of ranking keys by Q·K, Tauformer uses a different approach based on topological principles.
Below is a post-style overview of the idea and the first training signals from a 30M-parameter run.
You might also wanna read

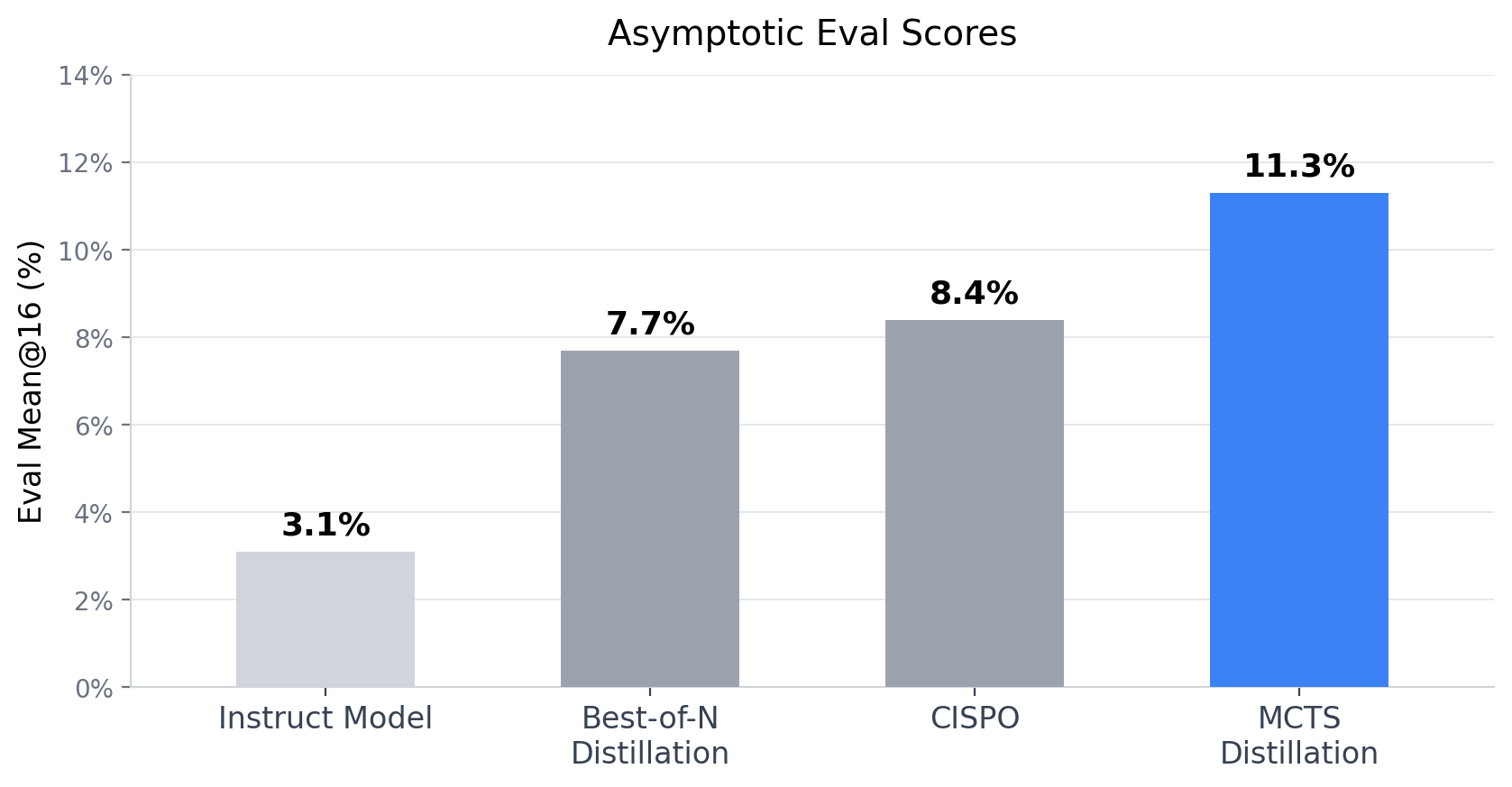
Applying Tree Search Techniques to Language Models: Lessons from AlphaZero and DeepSeek-R1
This article explores the application of tree search techniques (like those used in AlphaZero for board games) to language models, examining

Autonomous AI Research Agents for Single-GPU Nanochat Training Automation
The article describes an AI research automation project called 'autoresearch' that enables autonomous AI agents to conduct machine learning
 github.com·2mo ago
github.com·2mo ago
DeepSeek's mHC Architecture: Transforming Transformer Design with Multiple Residual Streams
The article discusses DeepSeek's novel mHC (multi-head connection) architecture that fundamentally changes transformer design by introducing
 taylorkolasinski.com·4mo ago
taylorkolasinski.com·4mo ago
Program of Thoughts: Separating Computation from Reasoning in Language Models for Numerical Tasks
The article introduces "Program of Thoughts" (PoT), a new approach that disentangles computation from reasoning in language models for numer

MMaDA-Parallel: Multimodal Diffusion Language Models for Thinking-Aware Generation and Editing
This article presents MMaDA-Parallel, a multimodal large diffusion language model for thinking-aware editing and generation. The research id
github.com·6mo ago
Fast-dLLM: Training-Free Acceleration Method for Diffusion Language Models Using KV Cache and Parallel Decoding
Researchers introduce Fast-dLLM, a training-free acceleration method for diffusion-based large language models that addresses their slower i