SparseLoCo: Communication-Efficient LLM Training with Extreme Compression via Sparsification and Quantization
By
synapz_org
Not artisan, but a perfectly fine bagel. Hits the spot.
Summary
SparseLoCo is a new communication-efficient training algorithm for Large Language Models (LLMs) that combines Top-k sparsification and quantization to achieve extreme compression ratios of 1-3% sparsity and 2-bit quantization. The method addresses communication bottlenecks in distributed LLM training across bandwidth-constrained environments like data centers and the internet, outperforming full-precision DiLoCo while reducing communication costs significantly.
Key quotes
· 4 pulledCommunication-efficient distributed training algorithms have received considerable interest recently due to their benefits for training Large Language Models (LLMs) in bandwidth-constrained settings
Despite reducing communication frequency, these methods still typically require communicating a full copy of the model's gradients-resulting in a communication bottleneck even for cross-datacenter links
SparseLoCo provides significant benefits in both performance and communication cost
Our key observations are that outer momentum can be locally approximated by an error feedback combined with aggressive sparsity and that sparse aggregation can actually improve model performance
You might also wanna read

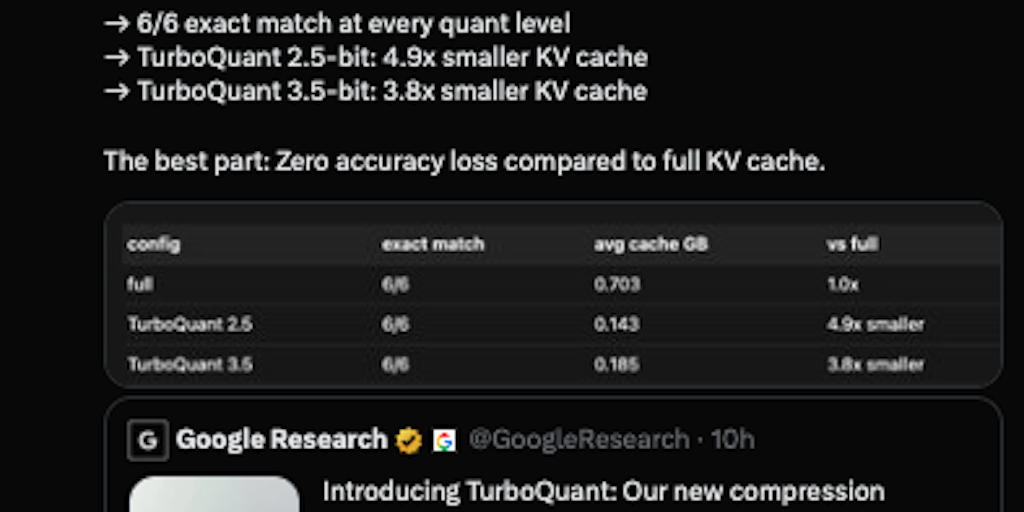
Google Introduces TurboQuant: Advanced LLM Compression Algorithm for Efficient AI Model Deployment
Google has developed TurboQuant, a new LLM compression algorithm that uses advanced theoretically grounded quantization techniques to enable
 Product Hunt·2mo ago
Product Hunt·2mo ago
Parametric Memory Law: A Quantitative Framework for Understanding LoRA Memory Capacity in LLMs
This research paper introduces the Parametric Memory Law, a quantitative framework for understanding how Low-Rank Adaptation (LoRA) enables

RTP-LLM: Alibaba's High-Performance Inference Engine for Large Language Model Deployment
This paper presents RTP-LLM, a high-performance inference engine developed by Alibaba for industrial-scale deployment of Large Language Mode