R2 - R2 Data Catalog now exposes metrics via the GraphQL Analytics API
1mo ago
Source
CloudflareR2 - R2 Data Catalog now exposes metrics via the GraphQL Analytics APIcloudflare.comR2 Data Catalog is a managed Apache Iceberg data catalog built directly into your R2 bucket that allows you to connect query engines like R2 SQL , Spark, Snowflake, and DuckDB to your data in R2. You can now query analytics for your R2 Data Catalog warehouses via Cloudflare's GraphQL Analytics API . Two new datasets are available: r2CatalogDataOperationsAdaptiveGroups tracks Iceberg REST API requests made to your catalog, including operation type, request duration, HTTP status, and request body bytes. Use this to monitor request volume and latency across warehouses, namespaces, and tables. r2CatalogTableMaintenanceAdaptiveGroups tracks table maintenance jobs such as compaction and snapshot expiration. Use this to monitor job success rates, files processed, bytes read and written, and job duration. Both datasets support filtering by warehouse name, namespace, table name, and time range. They also include percentile aggregations for duration metrics. For detailed schema information and example queries, refer to the R2 Data Catalog metrics and analytics documentation .
You might also wanna read


Cloudflare Launches Fully-Managed Data Platform for Analytical Data on Global Infrastructure
Cloudflare announced the Cloudflare Data Platform, a fully-managed suite of products for ingesting, storing, and querying analytical data. B
 blog.cloudflare.com·9mo ago
blog.cloudflare.com·9mo ago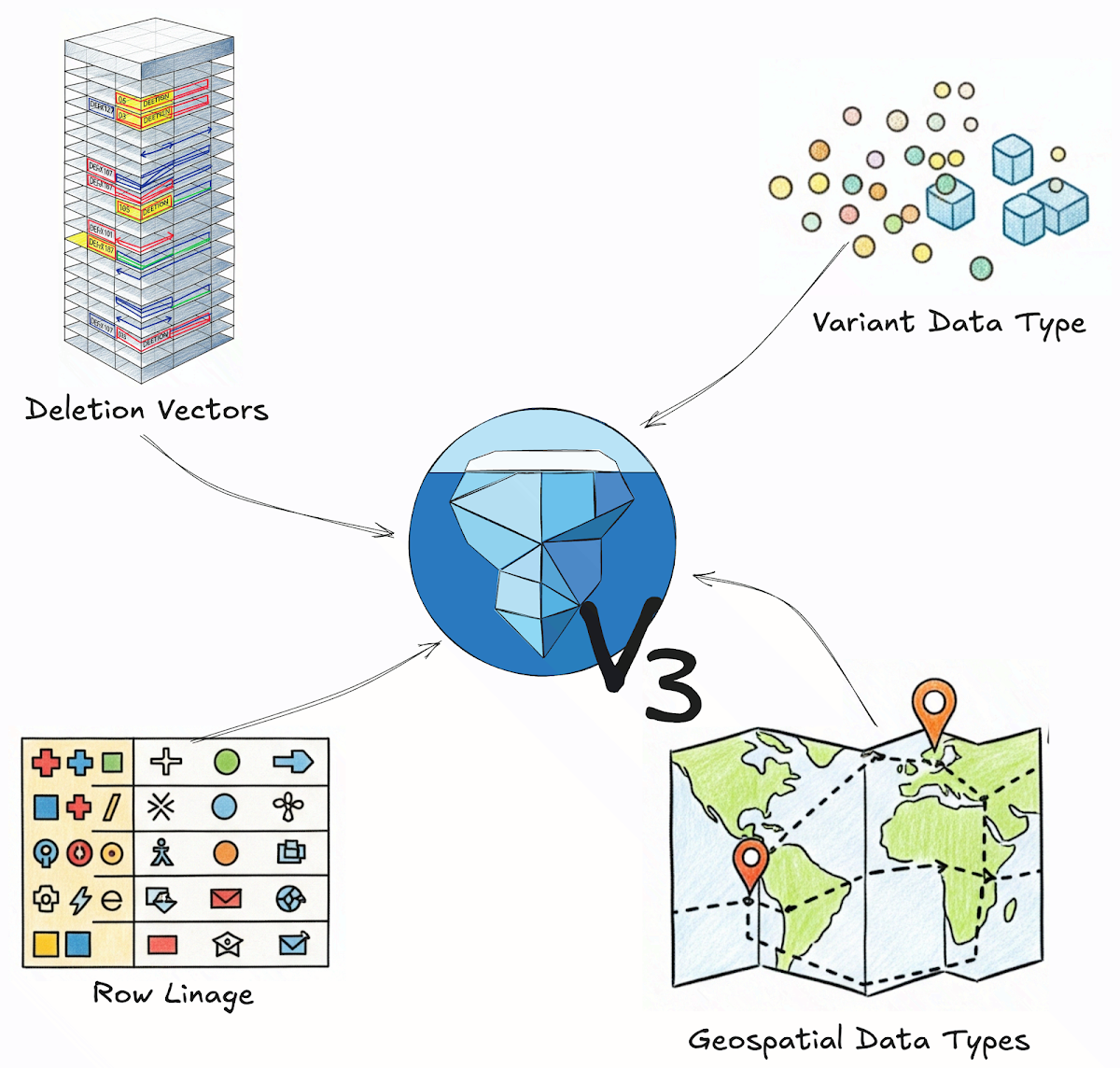
Key Enhancements in Apache Iceberg V3 for Data Lake Efficiency
The article discusses the new features in Apache Iceberg V3, focusing on improvements like more efficient row-level transactions with deleti
 opensource.googleblog.com·10mo ago
opensource.googleblog.com·10mo agoVersion 18.2
Microsoft·1mo ago

The Role of Apache Iceberg in Modern Data Infrastructure and the Equality Delete Problem
The article discusses the growing significance of Apache Iceberg in the data infrastructure landscape, highlighting major acquisitions by Da
 blog.dataengineerthings.org·10mo ago
blog.dataengineerthings.org·10mo ago
Performance Benchmark: Polars vs DuckDB vs Daft vs Spark on 650GB Delta Lake Dataset
The article presents a performance comparison benchmark of four data processing frameworks (Polars, DuckDB, Daft, and Spark) on a 650GB Delt
 dataengineeringcentral.substack.com·7mo ago
dataengineeringcentral.substack.com·7mo ago
Google and Schema.org release first public dataset on structured data adoption across millions of domains
Schema.org, in collaboration with Google, has published its first public dataset of aggregate usage statistics for structured data vocabular
 ppc.land·27d ago
ppc.land·27d ago
Comments
Sign in to join the conversation.
No comments yet. Be the first.