MobilityBench: A New Benchmark for Evaluating LLM-Based Route-Planning Agents Using Real-World Mobility Data
By
[Submitted on 26 Feb 2026 (v1), last revised 10 Jun 2026 (this version, v2)]
Crackles when you bite it. Shows the baker did the work.
Summary
This paper introduces MobilityBench, a scalable benchmark for evaluating LLM-based route-planning agents in real-world mobility scenarios. Built from anonymized real user queries from Amap (a mapping service), it covers diverse route-planning intents across multiple cities worldwide. The benchmark features a deterministic API-replay sandbox for reproducible evaluation and a multi-dimensional protocol assessing outcome validity, instruction understanding, planning, tool use, and efficiency. Evaluation of multiple LLM-based agents reveals they perform well on basic information retrieval and route planning but struggle significantly with preference-constrained route planning, highlighting gaps in personalized mobility applications.
Key quotes
· 5 pulledRoute-planning agents powered by large language models (LLMs) have emerged as a promising paradigm for supporting everyday human mobility through natural language interaction and tool-mediated decision making.
Systematic evaluation in real-world mobility settings is hindered by diverse routing demands, non-deterministic mapping services, and limited reproducibility.
We design a deterministic API-replay sandbox that eliminates environmental variance from live services.
Our findings reveal that current models perform competently on Basic information retrieval and Route Planning tasks, yet struggle considerably with Preference-Constrained Route Planning, underscoring significant room for improvement in personalized mobility applications.
We publicly release the benchmark data, evaluation toolkit, and documentation at https://github.com/AMAP-ML/MobilityBench.
You might also wanna read


SkillsBench: A Benchmark for Evaluating AI Agent Skills Across Diverse Tasks
SkillsBench is a new benchmark for evaluating how well AI agent skills work across diverse tasks. The benchmark includes 86 tasks across 11
PA Bench: A New Benchmark for Evaluating AI Web Agents on Real-World Personal Assistant Workflows
The article introduces PA Bench, a new benchmark for evaluating web-based AI agents on real-world personal assistant workflows. It addresses
 vibrantlabs.com·3mo ago
vibrantlabs.com·3mo ago
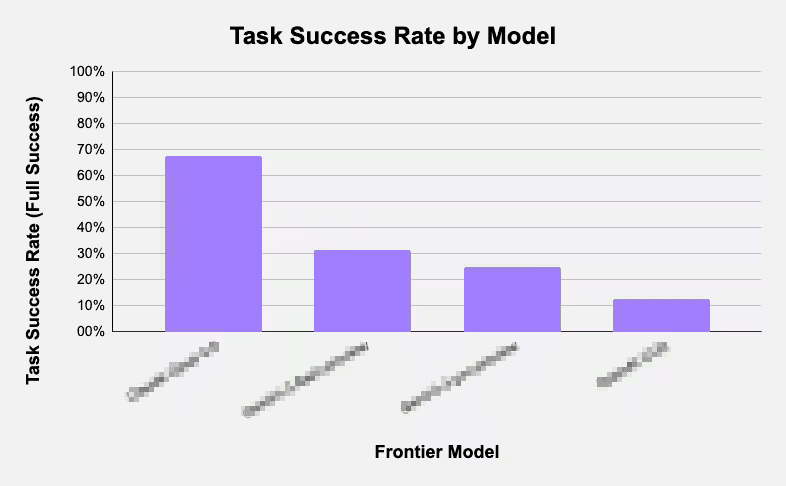
Web Bench: A Comprehensive Benchmark for AI Browser Agent Performance
Web Bench is a new benchmark platform designed to evaluate and compare AI browser agents' performance in web navigation tasks. It provides c
 Product Hunt·1y ago
Product Hunt·1y ago
SnapBench: A Spatial Reasoning Benchmark for LLMs Inspired by Pokémon Snap
SnapBench is a spatial reasoning benchmark for large language models (LLMs) inspired by the 1999 game Pokémon Snap. The system uses a vision
 github.com·4mo ago
github.com·4mo ago
Adaptive LLM Routing Using Contextual Bandits and Shared Embedding Space
This research paper proposes a novel approach to LLM routing that treats it as a contextual bandit problem rather than supervised learning.

ProgramBench: New Benchmark Reveals Language Models Struggle to Build Complete Software Projects From Scratch
This paper introduces ProgramBench, a new benchmark designed to evaluate the ability of language model-based software engineering agents to