SnapBench: A Spatial Reasoning Benchmark for LLMs Inspired by Pokémon Snap
By
beigebrucewayne
Slow-proofed and worth the wait. Worth its weight in flour.
Summary
SnapBench is a spatial reasoning benchmark for large language models (LLMs) inspired by the 1999 game Pokémon Snap. The system uses a vision-language model (VLM) to pilot a drone through a 3D world to locate and identify creatures, testing spatial reasoning capabilities. The architecture consists of three main components: a Rust-based controller for orchestration, a VLM (via OpenRouter) for processing screenshots and prompts, and a simulation environment built with Zig/raylib for game state management. The benchmark aims to evaluate how well LLMs can understand and navigate 3D spaces, with communication between components handled via UDP protocol on port 9999.
Key quotes
· 5 pulledInspired by Pokémon Snap (1999). VLM pilots a drone through 3D world to locate and identify creatures.
SnapBench: spatial reasoning benchmark for LLMs
Architecture consists of Controller (Rust), VLM (OpenRouter), and Simulation (Zig/raylib)
C -->|'screenshot + prompt'| V
C <-->|'cmds + state<br>**UDP:9999**'| S
You might also wanna read


Prompt Rewrite Boosts GPT-5-mini Performance by 22% on Tau² Benchmark
Researchers discovered that a simple prompt rewrite significantly boosted the performance of GPT-5-mini by 22% on the Tau² benchmark, which
 quesma.com·8mo ago
quesma.com·8mo ago
DeepSeek-V4: Hybrid Sparse-Attention Architecture Enables Efficient Million-Token Context Inference
DeepSeek-V4 introduces a hybrid sparse-attention architecture combined with on-policy distillation across domain specialists, enabling 1M-to
 artgor.medium.com·6h ago
artgor.medium.com·6h ago
LiveBrowseComp reveals LLM search agents rely on memorized knowledge, not genuine web searching
This paper introduces the concept of Intrinsic Knowledge Dependence (IKD), showing that LLM-based search agents often rely on pre-trained kn

New benchmark reveals AI models often cite wrong sources even when answers are correct
Researchers at Peking University have developed CiteVQA, a new benchmark that tests whether AI models can correctly cite source documents wh
 the-decoder.com·4d ago
the-decoder.com·4d ago
Orthrus: A Dual-Architecture Framework for Fast, Lossless LLM Inference via Diffusion Decoding
Orthrus is a dual-architecture framework that combines autoregressive LLMs with diffusion models to enable fast, lossless parallel token gen
 github.com·16d ago
github.com·16d ago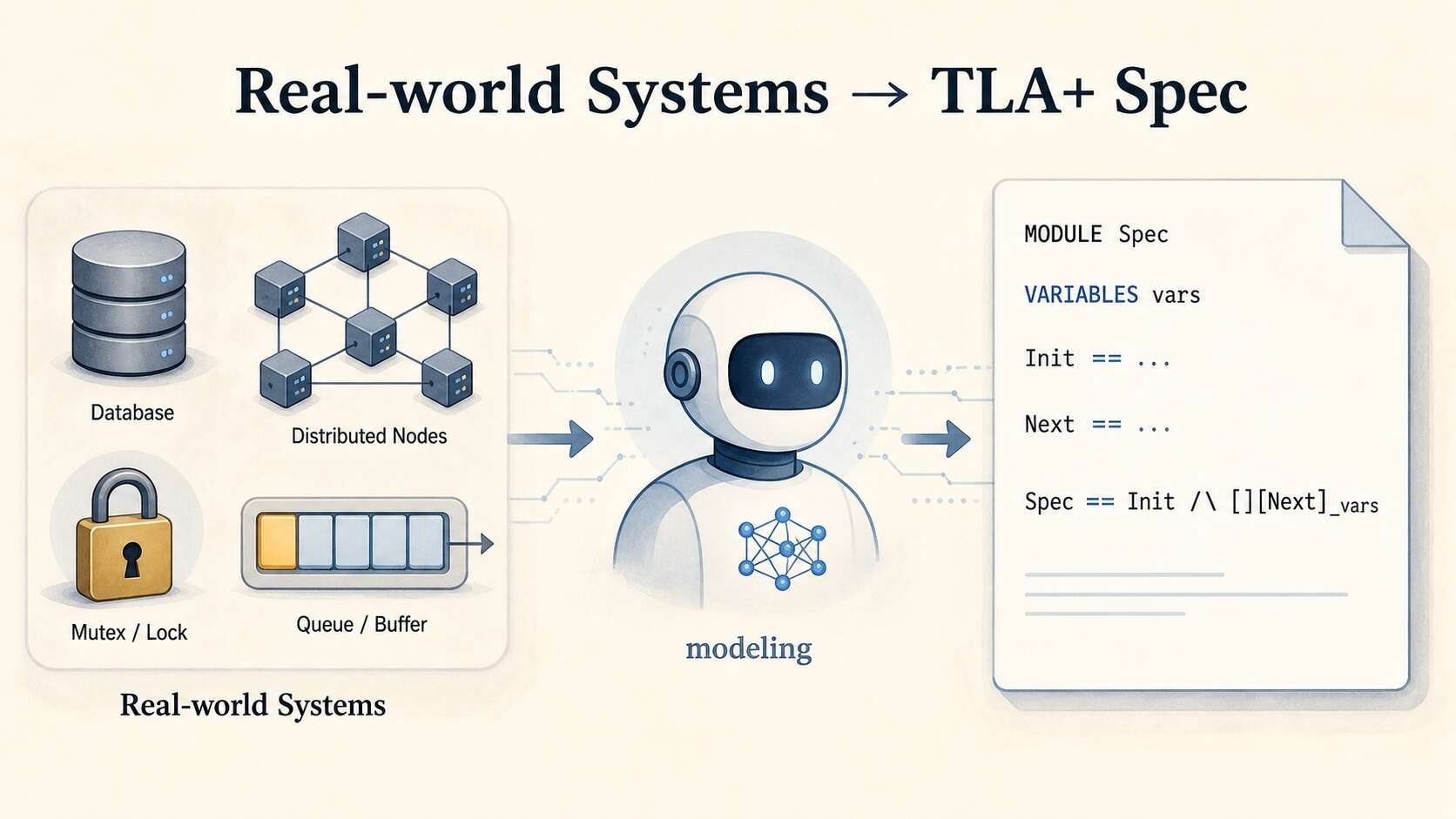
Evaluating LLMs for TLA+ System Modeling: The Specula Team's Experience with Claude and Raft
The Specula team evaluates LLMs (specifically Claude) on their ability to model real-world systems using TLA+, a formal specification langua