ProgramBench: New Benchmark Reveals Language Models Struggle to Build Complete Software Projects From Scratch
By
[Submitted on 5 May 2026]
A second-rack bagel that's nearly first-rack. Tasty stuff.
Summary
This paper introduces ProgramBench, a new benchmark designed to evaluate the ability of language model-based software engineering agents to build complete software projects from scratch. Unlike existing benchmarks that focus on narrow tasks like bug fixing or single feature development, ProgramBench requires agents to architect and implement entire codebases that match reference executable behavior, using only the program and its documentation. The benchmark includes 200 tasks ranging from simple CLI tools to complex software like FFmpeg, SQLite, and the PHP interpreter. Evaluation of 9 language models showed that none fully resolved any task, with the best model passing 95% of tests on only 3% of tasks. The study also found that models tend to produce monolithic, single-file implementations that differ significantly from human-written code.
Key quotes
· 5 pulledTurning ideas into full software projects from scratch has become a popular use case for language models.
Existing benchmarks measure focused, limited tasks such as fixing a single bug or developing a single, specified feature.
We evaluate 9 LMs and find that none fully resolve any task, with the best model passing 95% of tests on only 3% of tasks.
Models favor monolithic, single-file implementations that diverge sharply from human-written code.
End-to-end behavioral tests are generated via agent-driven fuzzing, enabling evaluation without prescribing implementation structure.
You might also wanna read

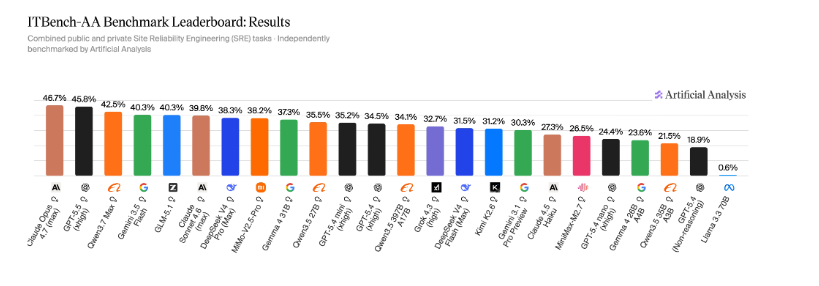
New ITBench-AA Benchmark Reveals AI Models Struggle with Enterprise SRE Tasks
ITBench-AA, a new benchmark developed by Artificial Analysis and IBM Research over six months, reveals that leading AI models like Claude Op
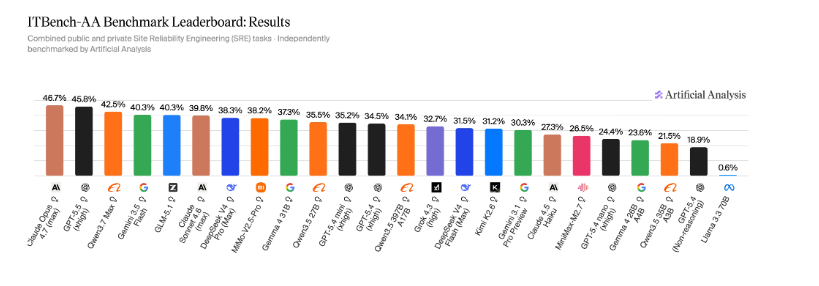
ITBench-AA Benchmark Launched: Frontier AI Models Score Below 50% on Enterprise IT Tasks
Artificial Analysis and IBM Software Innovation Lab have launched ITBench-AA, a new benchmark series evaluating AI models on agentic enterpr