Microsoft Open-Sources VibeVoice: A Speech-to-Text AI for Long-Form Audio Transcription
Open-Source Frontier Voice AI. Contribute to microsoft/VibeVoice development by creating an account on GitHub.
Read the full articleYou might also wanna read
How OpenAI's Whisper Turns Audio Into Text: A Developer's Guide
OpenAI's Whisper, released in 2022, became a widely adopted speech recognition model by converting audio into log-Mel spectrograms — image-l


VibeSonic: On-Device AI Voice Dictation Software for Mac with Privacy Focus
AI voice dictation that runs entirely on your Mac. No cloud, no subscription, no data leaving your device. On-device Whisper and NVIDIA Para
 Product Hunt·3mo ago
Product Hunt·3mo ago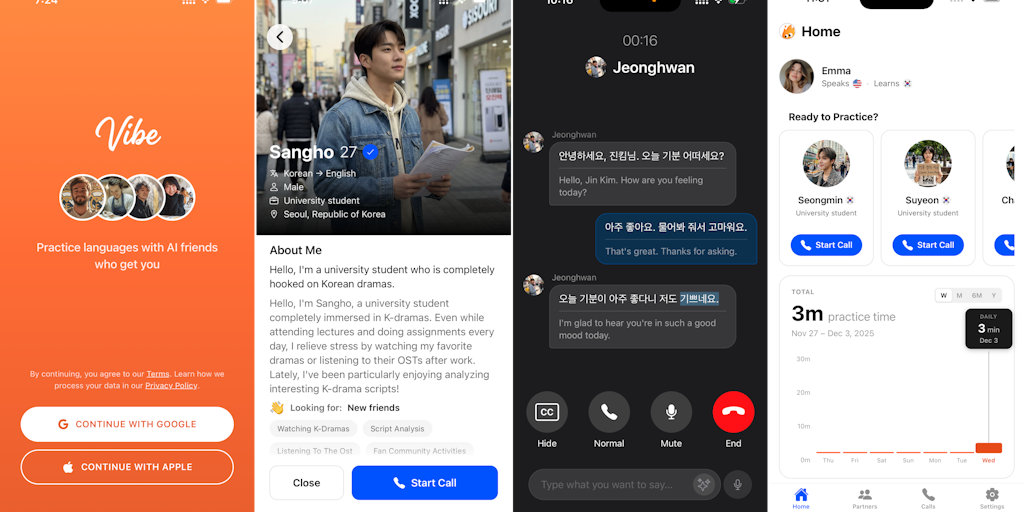
Vibe: AI Language Learning App with Personalized Conversation Partners
Vibe is an AI language learning app where beginners can speak from day one. Match with AI friends based on your interests and call them to p
Product Hunt·7mo ago
Microsoft Launches Free Copilot Audio Expressions Tool for Text-to-Speech Conversion
Meet the new Microsoft Copilot, your AI companion that remembers details (Memory), takes action (Actions), sees your world (Vision), and mor
Product Hunt·10mo agoBuilding a Multi-Channel AI Appointment Agent with AgenDuet, Bedrock Nova Sonic, and OpenClaw
A new guide outlines a robust architectural blueprint for an inbound clinic appointment assistant, "Claudia," designed to overcome common la
Developer Builds Zero-Setup Speaker Labeling Using Pitch Measurement, No AI Model Needed
A developer building the open-source audio analysis library 'audiotrace' needed a way to label speakers in call transcripts without requirin
Comments
Sign in to join the conversation.
No comments yet. Be the first.