Meta's Open-Source TTS Model for Tswana Now Runs on Huawei Ascend NPUs via Modelers.cn
By
AI China News
Summary
Meta's MMS TTS model for Tswana (a low-resource language spoken by ~8 million people in Southern Africa) has been made available on Modelers.cn and now runs on Huawei Ascend NPUs. This open-source text-to-speech model addresses the challenge of building voice interfaces for underrepresented languages, which typically suffer from tiny datasets and scarce, often proprietary models. The move makes TTS technology more accessible for Tswana-speaking developers and communities.
Source

 bskyMeta's Open-Source TTS Model for Tswana Now Runs on Huawei Ascend NPUs via Modelers.cnaichina.news
bskyMeta's Open-Source TTS Model for Tswana Now Runs on Huawei Ascend NPUs via Modelers.cnaichina.newsKey quotes
· 3 pulledIf you've ever tried to build a voice interface for a language that isn't English, Mandarin, or Spanish, you know the pain: datasets are tiny, models are scarce, and the few that exist are often locked behind proprietary APIs.
That's why the arrival of Meta's MMS TTS model for Tswana (ISO code tue) on Modelers.cn is genuinely good news.
It's an open-source, text-to-speech model for a language spoken by roughly eight million people in Southern Africa—and it now runs on Huawei Ascend NPUs, making it accessible to developers.
You might also wanna read


Meta Launches Omnilingual ASR Supporting Over 1,600 Languages
Meta introduces Omnilingual Automatic Speech Recognition (ASR), a suite of models that provides speech recognition capabilities for over 1,6
 ai.meta.com·7mo ago
ai.meta.com·7mo ago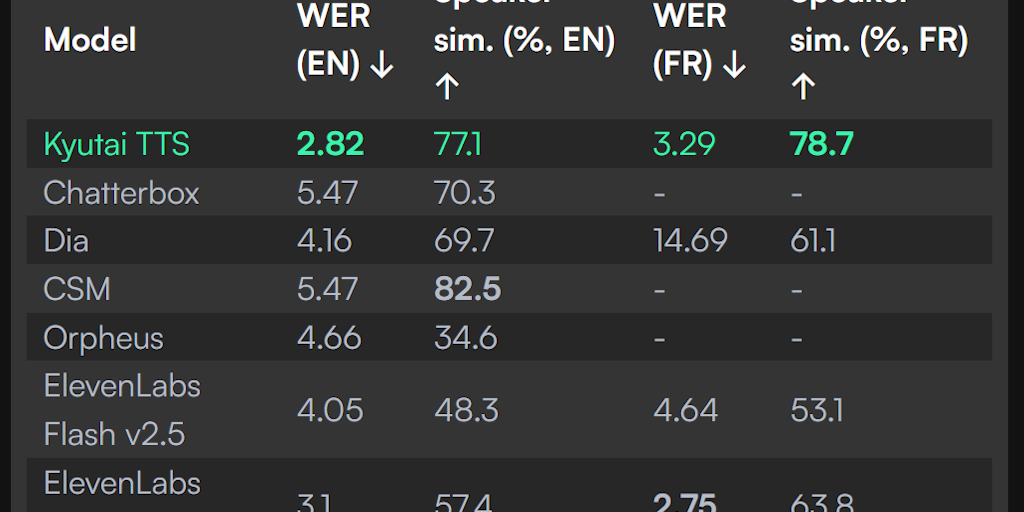
Kyutai TTS: Open-Source Text-to-Speech Model for Real-Time AI Applications
Kyutai TTS is an open-source text-to-speech model specifically optimized for real-time applications. It features streaming capabilities that
 Product Hunt·1y ago
Product Hunt·1y ago
Inworld launches TTS-2 with cross-lingual synthesis and natural language voice control
Inworld announces TTS-2, the successor to their #1 ranked text-to-speech model (TTS 1.5), featuring six major upgrades including natural lan
Product Hunt·2mo ago
Kitten TTS: A Lightweight, Open-Source Text-to-Speech Model
Kitten TTS is an open-source, lightweight text-to-speech model with 15 million parameters, designed for high-quality voice synthesis without
 github.com·3mo ago
github.com·3mo ago
Kitten TTS: A Lightweight 25MB AI Voice Model for CPU-Based Speech Synthesis
The article introduces Kitten TTS, a groundbreaking 25MB AI voice model that operates efficiently on CPUs without requiring GPUs or expensiv

Challenges with Open-Source Text-to-Speech Technology for Podcast Generation
The author discusses their experience with open-source text-to-speech (TTS) technology for converting blog posts into podcasts. They establi
 duarteocarmo.com·7mo ago
duarteocarmo.com·7mo ago
Comments
Sign in to join the conversation.
No comments yet. Be the first.