Large Language Models Enable Effective Deanonymization of Pseudonymous Online Users
We show that large language models can be used to perform at-scale deanonymization. With full Internet access, our agent can re-identify Hacker News users and Anthropic Interviewer participants at…
Read the full articleYou might also wanna read


How large language models could enable mass surveillance by lowering data analysis costs
The technology could make commercially available bulk datasets even more of a privacy concern.
 technologyreview.com·7d ago
technologyreview.com·7d ago
An investigation into code injection vulnerabilities caused by generative AI
This article looks at the potential security implications of large language models (LLMs), a text-producing form of generative AI.

Study finds large language models vulnerable to classic persuasion tactics for harmful requests
Are large language models (LLMs) susceptible to the same persuasive appeals as humans? We tested whether classic persuasion principles (auth
 pnas.org·1mo ago
pnas.org·1mo ago
Study Finds LLM Poisoning Attacks Require Only ~250 Documents Regardless of Model Size
Poisoning attacks can compromise the safety of large language models (LLMs) by injecting malicious documents into their training data. Exist
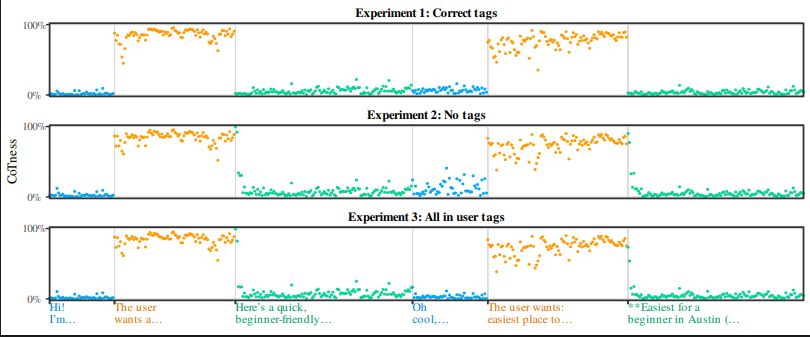
Prompt Injection Explained as a Role Confusion Problem in LLMs
LLMs can't tell who's speaking. We show they identify roles by writing style, not tags, and exploit this with CoT Forgery, injecting fake re
 role-confusion.github.io·18d ago
role-confusion.github.io·18d ago
LLMs: The Double-Edged Sword of Misinformation
Large language models (LLMs) now pose ecosystem-level security risks, not just content-level threats. A new framework helps address challeng
Comments
Sign in to join the conversation.
No comments yet. Be the first.