Why an Older AI Model Outperforms Newer Versions in Production Work
By
Vera Calloway
Summary
The author argues that newer, higher-benchmark AI models (like Claude Opus 4.7 and 4.8) can actually perform worse in production work compared to slightly older models (Claude Opus 4.6). The newer models score better on benchmarks but break practical functionality like file creation, suggesting that benchmark optimization doesn't always translate to real-world utility.
Source
 bskyWhy an Older AI Model Outperforms Newer Versions in Production Workhackernoon.com
bskyWhy an Older AI Model Outperforms Newer Versions in Production Workhackernoon.comKey quotes
· 3 pulledI use Claude Opus 4.6 over 4.7 and 4.8 for production work.
The newer models score higher on benchmarks but break file creation.
I Downgraded My AI and Output Got Better
You might also wanna read


Why Developers Prefer Claude AI for Practical Coding Work Over Benchmark-Leading Alternatives
The article examines why developers consistently choose Claude over other AI coding tools despite benchmark results favoring alternatives. T
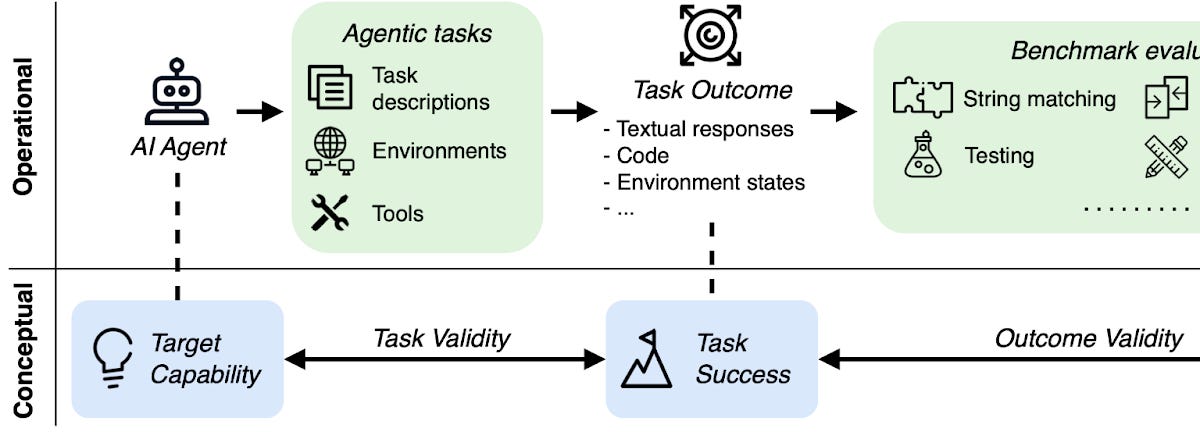
Why Current AI Agent Benchmarks Are Unreliable and Misleading
The article argues that current AI agent benchmarks are fundamentally flawed and unreliable. Unlike traditional AI benchmarks, agent benchma
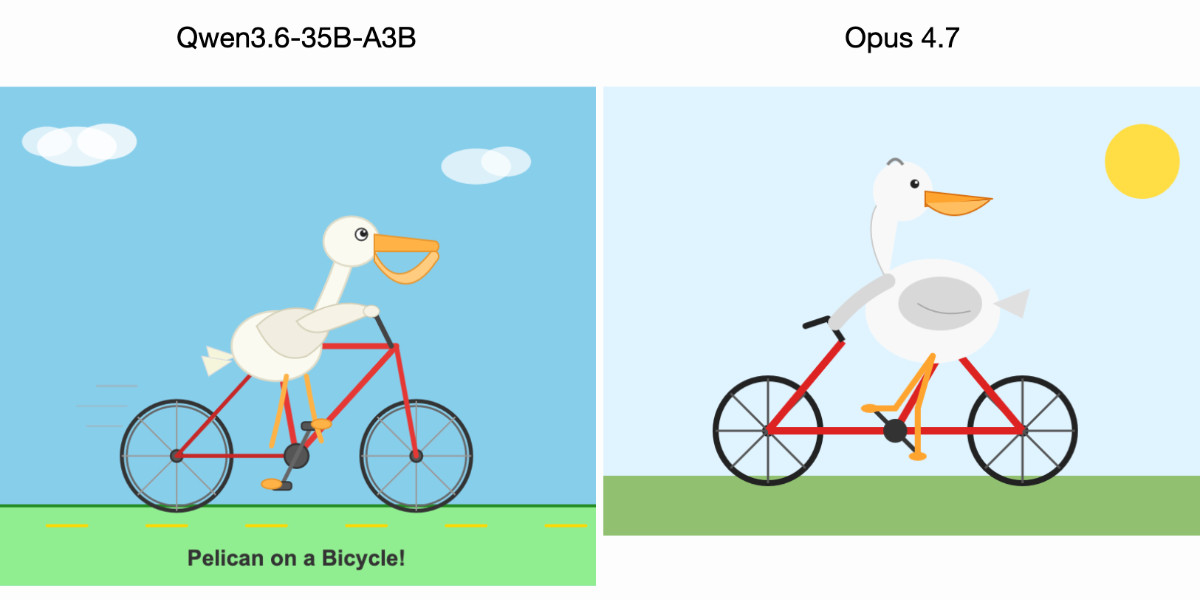
Benchmark Comparison: Qwen3.6-35B-A3B Outperforms Claude Opus 4.7 in Pelican Image Generation Test
The article presents a comparative benchmark test between two AI language models - Qwen3.6-35B-A3B from Alibaba and Claude Opus 4.7 from Ant
Introducing Claude Opus 4.8

Anthropic Launches Claude Opus 4.8 with Faster Performance and Lower Costs
Anthropic has released Claude Opus 4.8, an upgraded version of their flagship AI model, building on Opus 4.7 with improvements across benchm
 anthropic.com·23d ago
anthropic.com·23d ago
Claude Opus 4.6 AI Model Enhances Financial Analysis and Decision-Making
Claude Opus 4.6 represents an advancement in AI for financial applications, offering improved reasoning capabilities for complex analyses, c
 claude.com·4mo ago
claude.com·4mo ago