Grok Build 0.1 0616: Comprehensive AI Model Benchmarking and Competitive Analysis
By
himata4113
Summary
This article provides an in-depth analysis of xAI's Grok Build 0.1 0616, comparing it against other AI models across key metrics including intelligence quality, price, performance (tokens per second and time to first token), and context window capabilities. It references the Artificial Analysis Intelligence Index v4.1, which incorporates nine evaluations such as GPQA Diamond, SciCode, Humanity's Last Exam, and others to benchmark model intelligence. The analysis positions Grok within the broader competitive landscape of AI models.
Source

 Hacker NewsGrok Build 0.1 0616: Comprehensive AI Model Benchmarking and Competitive Analysisartificialanalysis.ai
Hacker NewsGrok Build 0.1 0616: Comprehensive AI Model Benchmarking and Competitive Analysisartificialanalysis.aiKey quotes
· 3 pulledArtificial Analysis Intelligence Index v4.1 incorporates 9 evaluations: GDPval-AA v2, 𝜏³-Banking, Terminal-Bench v2.1, SciCode, Humanity's Last Exam, GPQA Diamond, CritPt, AA-Omniscience, AA-LCR
Reasoning models are indicated by a lightbulb icon
See Intelligence Index methodology for further details, including a breakdown of each evaluation
You might also wanna read


xAI Releases Grok Build 0.1 Coding Model to Developers via Public API Beta
xAI has released Grok Build 0.1, its fastest coding model, to developers via the xAI API in public beta. Previously limited to paying subscr
 devops.com·23d ago
devops.com·23d ago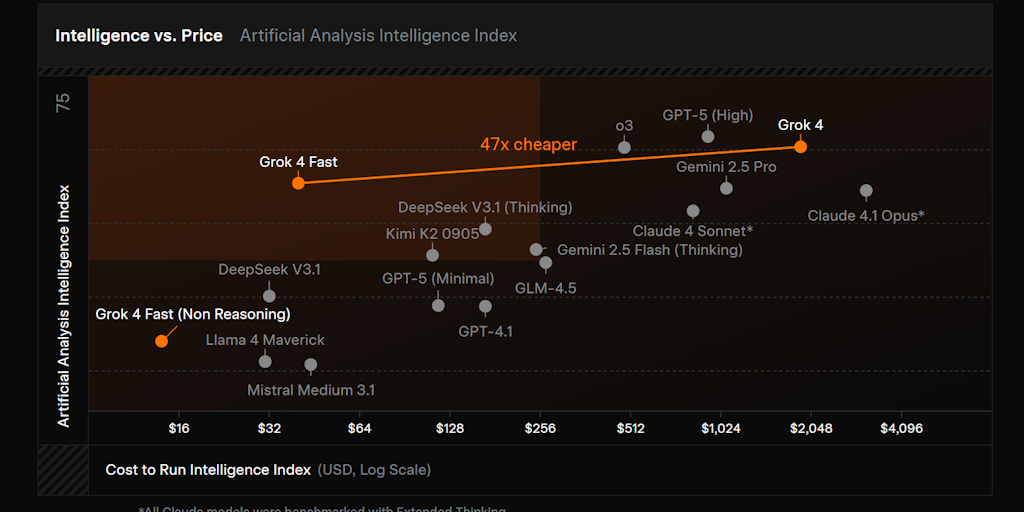
xAI Launches Grok 4 Fast AI Model with Free Access and Competitive Pricing
xAI has launched Grok 4 Fast, a new AI model that offers high speed (190 tokens per second), low cost ($0.20/1M input tokens, $0.50/1M outpu
 Product Hunt·4mo ago
Product Hunt·4mo ago
Grok: xAI's Free AI Assistant for Real-Time Search and Analysis
Grok is a free AI assistant developed by xAI that aims to maximize truth and objectivity. The AI tool offers features including real-time se
Product Hunt·11mo ago
Grok: xAI's Free AI Assistant for Real-Time Search and Analysis
Grok is a free AI assistant developed by xAI that aims to maximize truth and objectivity. The AI tool offers features including real-time se
Product Hunt·1mo ago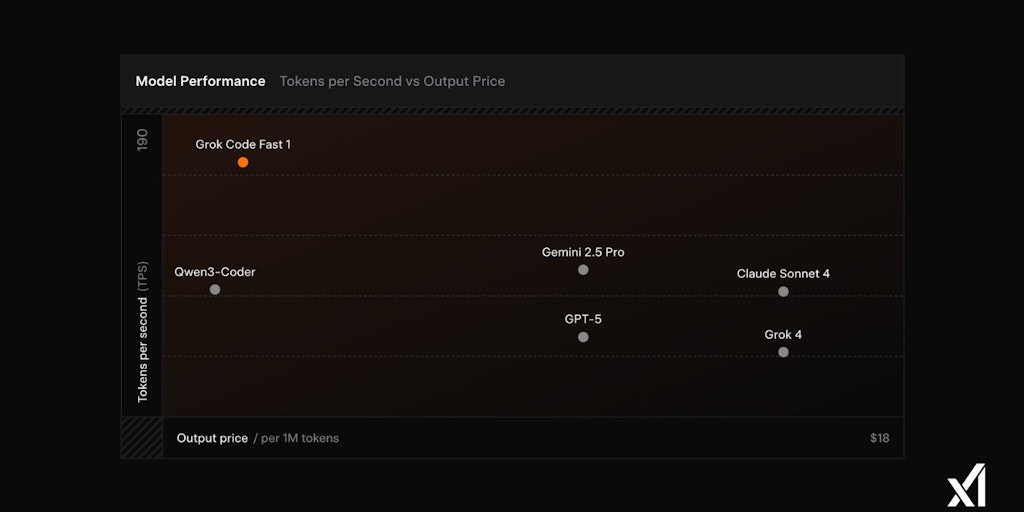
xAI Launches Grok Code Fast 1: Speedy and Economical AI Coding Assistant
Grok Code Fast 1 is a new AI coding assistant from xAI designed specifically for agentic coding workflows. It's built from scratch to be fas
Product Hunt·9mo ago
Microsoft Proceeds Cautiously with Grok 4 Rollout on Azure AI Foundry
Microsoft is proceeding cautiously with the rollout of Grok 4 on Azure AI Foundry, following concerns related to its predecessor models. The
Comments
Sign in to join the conversation.
No comments yet. Be the first.