GPU Programming Project: Implementing Parallelizable RNNs with CUDA
By
omegablues
If you only eat one bagel today, this is the bagel.
Summary
A student's final project for CS179: GPU Programming implementing the paper "Were RNNs All We Needed?" by Feng et al. The project focuses on creating simplified versions of GRUs and LSTMs (minGRU and minLSTM) that can be parallelized using the parallel scan algorithm, transforming their training and inference from O(T) sequential to O(log T) parallel processes for GPU acceleration. The implementation is done in CUDA to verify the paper's claims about making recurrent neural networks more efficient on GPUs.
Key quotes
· 3 pulledThe paper's core claim is that by making minor simplifications to LSTMs and GRUs, their recurrence can be expressed in a form amenable to the parallel scan algorithm
This changes their training and inference from an O(T) sequential process into an O(log T) parallel one, which helps with GPU acceleration
My goal was to verify this claim by building both the simplified models (minGRU and minLSTM) and a custom CUDA implementation
You might also wanna read


Rotary GPU: Enabling Large Mixture-of-Experts Models on Consumer Laptop GPUs with Limited Memory
This paper presents Rotary GPU, an exploratory approach to running large Mixture-of-Experts (MoE) language models on consumer-grade hardware

Unsloth and NVIDIA Partner to Accelerate LLM Fine-Tuning by 20%
Unsloth has partnered with NVIDIA to optimize fine-tuning of large language models, achieving 20% faster training speeds. The collaboration
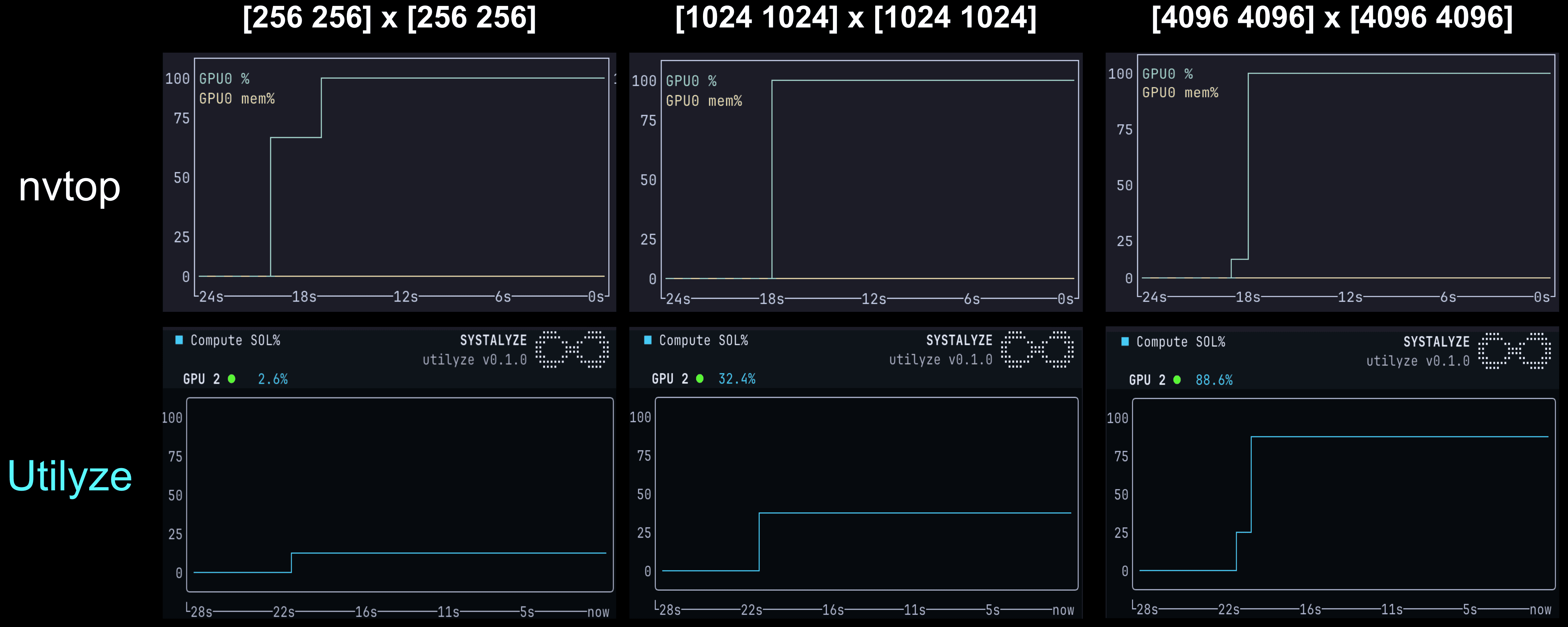
Systalyze's Utilyze Tool Reveals True GPU Compute Utilization in AI Workloads
Systalyze introduces Utilyze, a GPU compute utilization monitoring tool that reveals actual compute throughput versus traditional metrics li
 systalyze.com·1mo ago
systalyze.com·1mo ago
Eyot: A Programming Language That Makes GPU Programming as Simple as Background Threads
Eyot is a new programming language designed to make GPU programming as simple as spawning background threads. It transparently compiles code
 cowleyforniastudios.com·2mo ago
cowleyforniastudios.com·2mo ago
BarraCUDA: Open-Source CUDA Compiler Supports AMD, NVIDIA, and Tenstorrent GPUs
BarraCUDA is an open-source CUDA C++ compiler written from scratch in C99 that can compile .cu files to multiple GPU architectures including
 github.com·3mo ago
github.com·3mo ago
VectorWare Enables Rust Async/Await Programming on GPUs
VectorWare announces a breakthrough in GPU programming by enabling Rust's async/await and Future trait on GPUs. This represents a significan