Building a Metadata-Aware RAG Chatbot for Household Questions via Local LLM Fine-Tuning
By
Author Torgeir Helgevold
Summary
A personal project describes building a chatbot for household questions (maintenance, appointments, etc.) that uses RAG with a vector database. The key innovation is a pre-processing step that categorizes incoming questions into metadata categories (e.g., pool, car, HVAC, cooking) before querying, narrowing the vector search space to only relevant indexed entries for better retrieval results.
Source
 Hacker NewsBuilding a Metadata-Aware RAG Chatbot for Household Questions via Local LLM Fine-Tuningteachmecoolstuff.com
Hacker NewsBuilding a Metadata-Aware RAG Chatbot for Household Questions via Local LLM Fine-Tuningteachmecoolstuff.comKey quotes
· 5 pulledAs a fun personal project, I have been working on a chatbot for answering general questions about my household on anything from maintenance questions to doctor's appointments.
The general idea is that the chatbot will get its household knowledge through RAG from querying a vector database, but for better results I have made the vector searches metadata aware.
Basically, I am running questions through a pre-processing step to categorize questions into known metadata categories (e.g. pool, car, hvac, cooking).
The main goal of this is to narrow down the search space for vector ranking to only indexed entries that match the category of the question.
As an example, the question 'When did we replace our pool pump?' will be mapped to a category called 'pool' before querying the Index database.
As a fun personal project, I have been working on a chatbot for answering general questions about my household on anything from maintenance questions to doctor’s appointments.
The general idea is that the chatbot will get its household knowle
You might also wanna read


Vectorize Platform Releases New RAG Pipeline Features Including Hosted Chat Agent and Remote MCP Support
Vectorize, a data platform for retrieval augmented generation (RAG), has released new features including a fully hosted, no-code agentic cha
 Product Hunt·9mo ago
Product Hunt·9mo ago
Building a Minimal RAG System from Scratch: PDF to Highlighted Answers in ~100 Lines of Python
A hands-on tutorial that builds the smallest functional RAG (Retrieval-Augmented Generation) system from scratch using about 100 lines of Py
 towardsdatascience.com·22d ago
towardsdatascience.com·22d ago
IgnitionRAG: Managed RAG Backend Platform for Document Ingestion and AI Agent Deployment
IgnitionRAG is a managed RAG (Retrieval-Augmented Generation) backend platform that enables users to ingest various document types (PDF, DOC
Product Hunt·2mo ago
Empirical Study Finds Grep Outperforms Vector Retrieval in LLM Agentic Search Systems
This paper presents an empirical study comparing grep-based retrieval versus vector retrieval in LLM agentic search systems. Using a 116-que
Empirical Study Finds Grep Outperforms Vector Retrieval in LLM Agentic Search Systems
This paper presents an empirical study comparing grep-based retrieval versus vector retrieval in LLM agentic search systems. Using a 116-que

Amazon Bedrock Managed Knowledge Base simplifies enterprise RAG pipeline management for AI applications
Amazon Web Services announced Amazon Bedrock Managed Knowledge Base, a fully managed service that simplifies building enterprise-grade gener
 aws.amazon.com·1d ago
aws.amazon.com·1d agoAmazon Bedrock Managed Knowledge Base simplifies enterprise RAG pipeline management for AI applications
Amazon Web Services announced Amazon Bedrock Managed Knowledge Base, a fully managed service that simplifies building enterprise-grade gener
aws.amazon.com·1d ago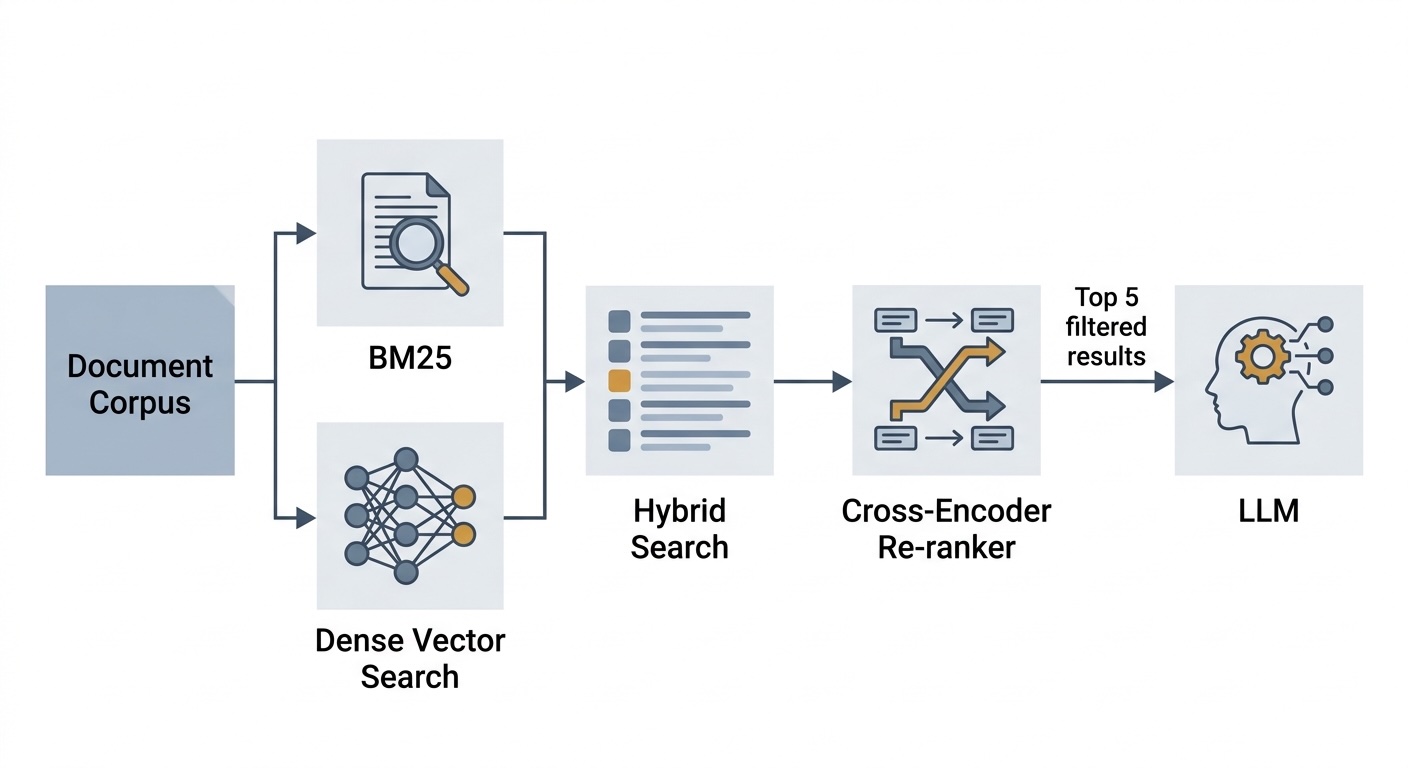
Hybrid Search and Re-Ranking: Improving RAG Accuracy Beyond Semantic Search
The article discusses the limitations of semantic search in Retrieval-Augmented Generation (RAG) systems, illustrated through a real-world e
towardsdatascience.com·7d agoComments
Sign in to join the conversation.
No comments yet. Be the first.