Fish Audio S1: Expressive Voice Cloning and Text-to-Speech Technology Launch
By
Ryan Hoover
Right out the toaster. Reliable, with some real depth.
Summary
Fish Audio has launched its S1 text-to-speech model, which the company claims is the most expressive and natural TTS model available. The technology can clone human voice nuances including accent, timbre, and speaking habits from just 10 seconds of audio, while maintaining emotional expressiveness and emphasis. The company emphasizes a human-first approach to AI voice technology, aiming to capture diverse voices with emotional connection and empathy. The product is built by the open-source team behind So-VITS-SVC and Bert-VITS2.
Key quotes
· 5 pulledFish Audio is the first model that can clone the nuances of human speech, including accent, timbre, and speaking habits, all while being expressive, emotional, and emphatic (with just 10 seconds of audio).
With all the AI slop going over our heads, it's more important than ever to be human-first.
We are taking the lead by making sure AI voices can capture the tiniest nuances of all the diverse voices out there.
Our voices can feel, empathize, and connect.
Fish Audio Voice Clone recreates a natural voice from just 10 seconds of audio—preserving accent, tone, and speaking habits.
You might also wanna read


VibeVoice: An Open-Source Text-to-Speech Framework for Expressive Multi-Speaker Audio Generation
VibeVoice is a novel open-source framework for generating expressive, long-form, multi-speaker conversational audio (like podcasts) from tex
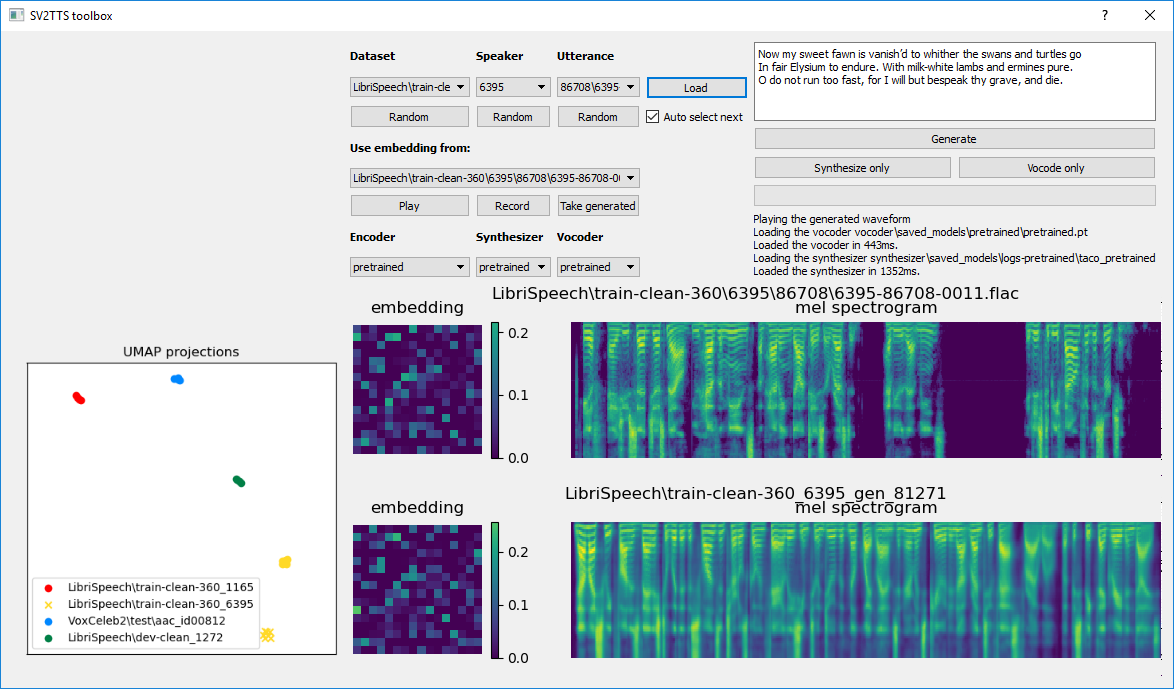
Real-Time Voice Cloning Implementation Using SV2TTS Deep Learning Framework
This repository implements a real-time voice cloning system called SV2TTS (Transfer Learning from Speaker Verification to Multispeaker Text-
 github.com·8mo ago
github.com·8mo ago
Microsoft Open-Sources VibeVoice: A Speech-to-Text AI for Long-Form Audio Transcription
Microsoft has open-sourced VibeVoice, a frontier voice AI system that includes VibeVoice-ASR, a unified speech-to-text model capable of hand
github.com·1mo ago
Kitten TTS: A Lightweight 25MB AI Voice Model for CPU-Based Speech Synthesis
The article introduces Kitten TTS, a groundbreaking 25MB AI voice model that operates efficiently on CPUs without requiring GPUs or expensiv