VibeVoice: An Open-Source Text-to-Speech Framework for Expressive Multi-Speaker Audio Generation
By
lastdong
Pure flour-power. Hearty enough to carry you through lunch.
Summary
VibeVoice is a novel open-source framework for generating expressive, long-form, multi-speaker conversational audio (like podcasts) from text. It addresses key challenges in traditional TTS systems including scalability, speaker consistency, and natural turn-taking. A core innovation is its use of continuous speech tokenizers (Acoustic and Semantic) operating at an ultra-low frame rate of 7.5 Hz, enabling more natural and efficient speech generation.
Key quotes
· 3 pulledVibeVoice is a novel framework designed for generating expressive, long-form, multi-speaker conversational audio, such as podcasts, from text.
It addresses significant challenges in traditional Text-to-Speech (TTS) systems, particularly in scalability, speaker consistency, and natural turn-taking.
A core innovation of VibeVoice is its use of continuous speech tokenizers (Acoustic and Semantic) operating at an ultra-low frame rate of 7.5 Hz.
You might also wanna read

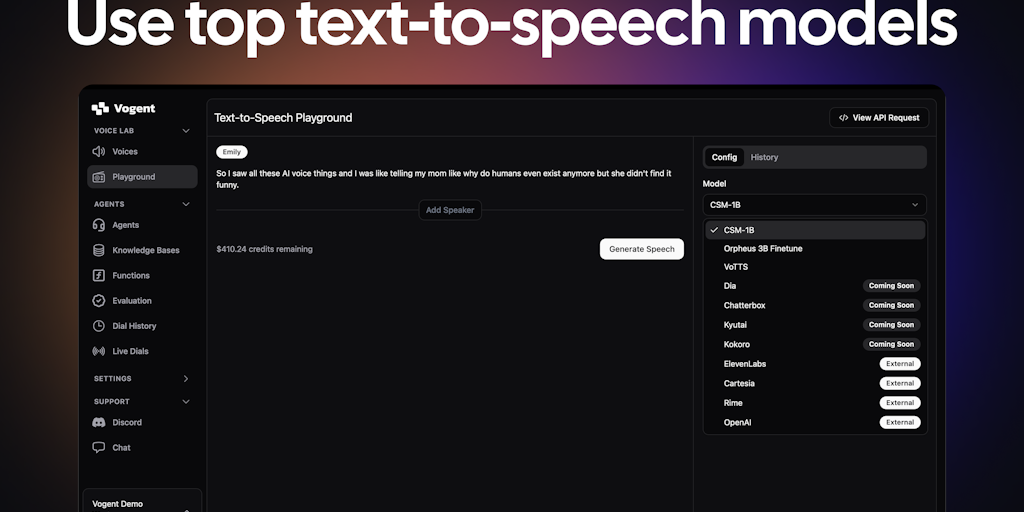
Vogent Voicelab: Platform for Optimized Open-Source Voice Model Inference
Vogent Voicelab is a platform that optimizes and post-trains top open-source voice models like Sesame's CSM-1B, Dia, and Chatterbox to gener
 Product Hunt·10mo ago
Product Hunt·10mo ago
Voiser AI: Human-like AI voiceover platform with 140+ languages and 1000+ voices
Voiser is an AI voiceover platform that converts text into human-like speech, supporting 140+ languages and 1000+ AI voices. It offers emoti
Product Hunt·13d ago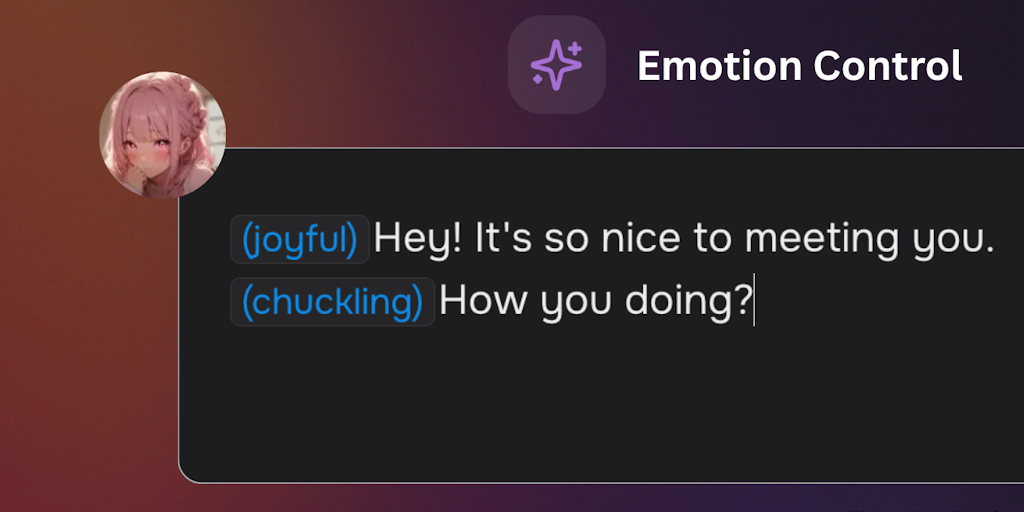
Fish Audio S1: Expressive Voice Cloning and Text-to-Speech Technology Launch
Fish Audio has launched its S1 text-to-speech model, which the company claims is the most expressive and natural TTS model available. The te
Product Hunt·2mo ago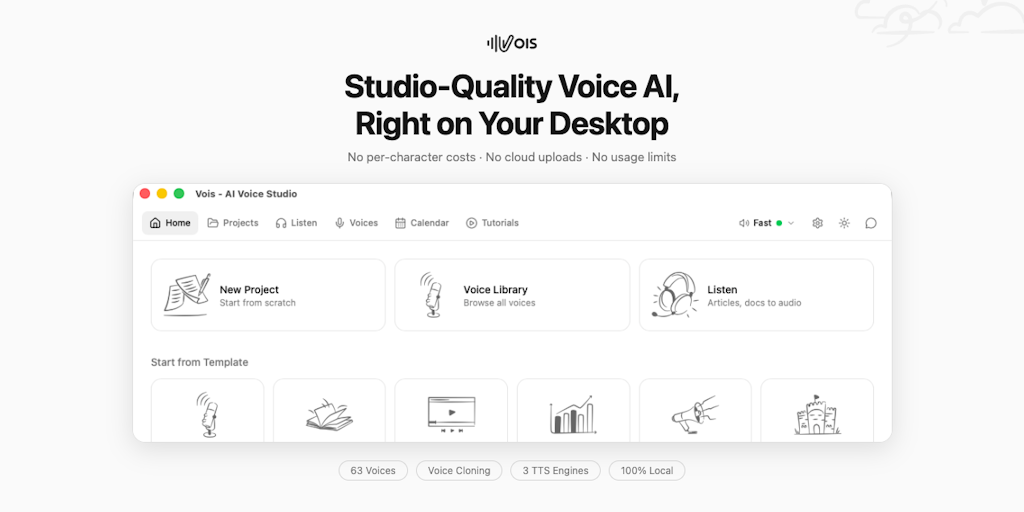
Vois: Desktop Voice Studio for Local Text-to-Speech and Voice Cloning
Vois is a desktop voice studio application that enables users to convert text content like scripts, ebooks, articles, and podcasts into natu
Product Hunt·2mo ago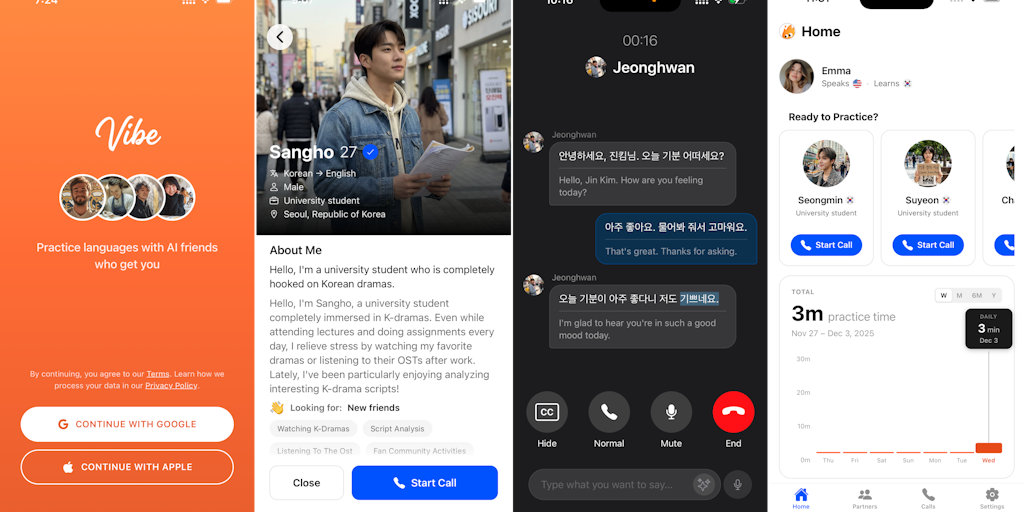
Vibe: AI Language Learning App with Personalized Conversation Partners
Vibe is an AI-powered language learning app that enables beginners to practice speaking from day one by matching users with AI conversation
Product Hunt·5mo ago
Open Vibe: AI-Powered SaaS Tutor That Guides Users Through Building Full-Stack Apps
Open Vibe is a SaaS-building platform that uses AI agents (like Claude Code) as personalized tutors to guide users through building full-sta
Product Hunt·27d ago