Why AI visibility dashboards sell false precision — and what brands should demand instead
By
Arber Xhindoli
Summary
A software engineer critically examines the emerging category of AI visibility measurement tools, arguing that these dashboards present precise metrics (rank, share of voice, mention rate) without disclosing the underlying methodology, variance, distribution, or raw data. The piece contends that the numbers are misleading because they lack statistical rigor, ignore the probabilistic and non-deterministic nature of AI model outputs, and sell false precision to brands seeking to measure their presence in AI-generated answers. The author calls for transparency, skepticism, and better measurement standards.
Source

 Hacker NewsWhy AI visibility dashboards sell false precision — and what brands should demand insteadcanonry.ai
Hacker NewsWhy AI visibility dashboards sell false precision — and what brands should demand insteadcanonry.aiKey quotes
· 3 pulledI've spent enough time building and debugging measurement systems to know when a dashboard is asking you to trust a number it cannot support.
When a tool says you are number four in your category, moved up two spots this week, or sit at 17% visibility while your competitor sits at 22%, it is asking you to believe in a level of precision that the underlying data simply cannot sustain.
The numbers look clean. The methodology is a black box. And the incentives are aligned to sell confidence, not accuracy.
You might also wanna read


Why AI Search Visibility Metrics Are Misleading and What to Measure Instead
This article argues that most AI search visibility tools are measuring the wrong metric — counting citations and mentions rather than actual
 nohacks.co·3d ago
nohacks.co·3d agoThe micro-macro shift: How to measure AI visibility now that precision is gone

AI Visibility Depends on Operational Alignment, Not Just SEO
The article argues that AI visibility for organizations depends less on traditional SEO tactics and more on operational alignment — specific
 searchenginejournal.com·9d ago
searchenginejournal.com·9d agoDesigning Transparency for Agentic AI Systems: Finding the Right Moments for Clarity
This article explores the design challenges of agentic AI systems, focusing on how to provide appropriate transparency without overwhelming
 Smashing Magazine·2mo ago
Smashing Magazine·2mo ago
Why AI benchmarks fail to measure real-world performance — and what should replace them
The article argues that current AI benchmarking methods are fundamentally broken because they evaluate AI performance in isolation (task-lev
 technologyreview.com·1d ago
technologyreview.com·1d ago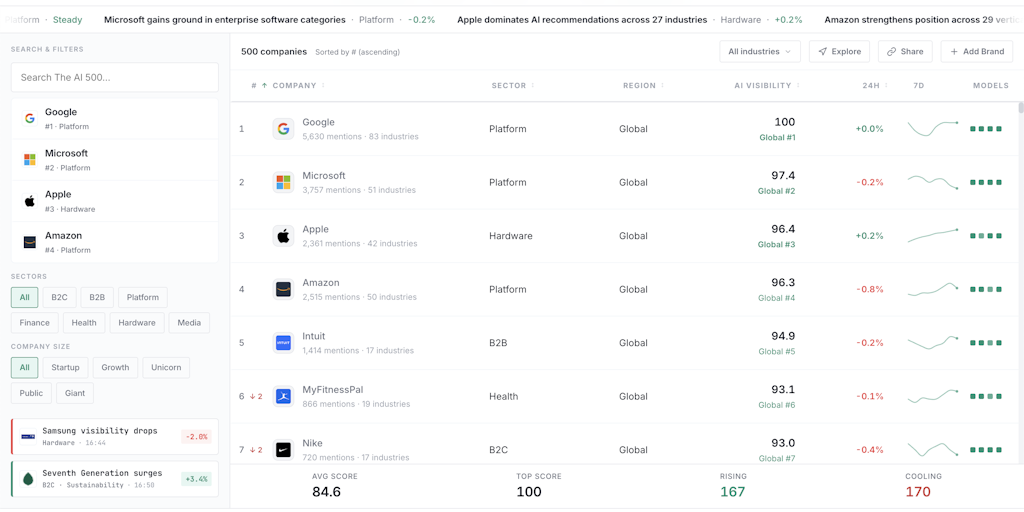
AI 500: Public Benchmark Tracking Brand Visibility Across Major AI Models
The article introduces the AI 500, a public benchmark tracking AI brand visibility across major AI models (ChatGPT, Claude, Gemini, Perplexi
 Product Hunt·7mo ago
Product Hunt·7mo ago
Comments
Sign in to join the conversation.
No comments yet. Be the first.