DynaFLIP: A Dynamics-Aware Multimodal Pre-Training Framework for Robot Manipulation Perception
By
[Submitted on 28 May 2026]
Summary
DynaFLIP is a dynamics-aware multimodal pre-training framework for robot manipulation perception. It constructs image-language-3D flow triplets from human and robot videos to train visual encoders that understand motion, not just static scenes. The framework uses simplex-volume minimization with a cosine regularizer and contrastive objective to align three modalities in a shared hyperspherical space. DynaFLIP representations serve as reusable visual backbones that outperform baselines across diverse downstream policies, including Vision-Language-Action models (VLAs), with gains up to +22.5% in out-of-distribution scenarios. The key insight is that robot generalization improves when visual representations encode how the world changes under action, not just what is present.
Source

Key quotes
· 5 pulledWe introduce DynaFLIP, a dynamics-aware multimodal pre-training framework that pushes motion understanding upstream into perception.
Our key idea is to encourage the three modalities to span a small simplex volume in the shared hyperspherical space -- a smaller simplex volume indicating stronger alignment.
Our results suggest that robot generalization improves when visual representations are trained to encode not just what is present, but how the world changes under action.
We validate this across diverse simulation and real-world setups, with gains reaching +22.5% under out-of-distribution scenarios.
Our analyses show that DynaFLIP focuses on control-relevant regions critical for manipulation.
You might also wanna read

Action Images: End-to-End Robotic Policy Learning via Multiview Video Generation
Action Images is an end-to-end framework for robotic policy learning that uses multi-view images and text instructions to jointly generate R
 github.com·10h ago
github.com·10h ago
Ultralytics YOLO26: A Unified Real-Time Vision Model Family with NMS-Free Inference and Advanced Training Pipeline
Ultralytics YOLO26 is a new family of real-time vision models that addresses key limitations of prior YOLO detectors. It introduces a dual-h
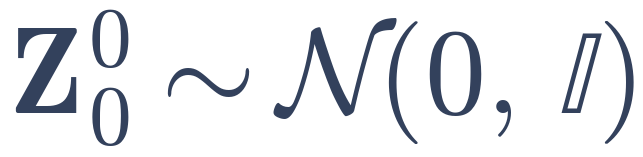
Lift4D: A Method for Single-View 4D Dynamic Scene Reconstruction Using Gaussian Splatting
This article presents Lift4D, a novel methodology for reconstructing 4D (3D + time) dynamic scenes from single-view video input. The approac
Capybara: A Unified Visual Creation Model for Visual Synthesis and Editing
Capybara is a unified visual creation model and framework for high-quality visual synthesis and manipulation tasks. It leverages advanced di
github.com·4mo ago
ByteDance Releases Lance: A 3B-Parameter Unified Multimodal Model for Image and Video Tasks
ByteDance has released Lance, a 3B-active-parameter native unified multimodal model capable of handling image and video understanding, gener
github.com·1mo ago
StreamingVLM: Real-Time Vision-Language Model for Infinite Video Stream Processing
StreamingVLM is a new vision-language model designed for real-time understanding of infinite video streams, addressing the computational cha
Comments
Sign in to join the conversation.
No comments yet. Be the first.