Command-Line Tools Outperform Hadoop by 235x for Moderate-Scale Data Processing
Adam Drake is an advisor to scale-up tech companies. He writes about ML/AI/data, leadership, and building tech teams.
Read the full articleYou might also wanna read
Simulating Database Performance Under Load with Speedscale
Big data storage tools like BigQuery, Hadoop, and Cassandra are used to manage large volumes of structured and unstructured data generated b


A beginner's guide to computing clusters: how distributed computing powers modern data analysis
Your humble laptop can only do so much. Here's your beginner's guide to computing clusters!
Iterating terabyte-sized ClickHouse® tables in production
Schema migrations on a streaming ClickHouse table? At 100s of MB/s? Here's how we do it across clusters without losing a single bit.
Build fast software with big data requirements
Somehow we got stuck on the idea that big data systems should be slow. We're making it fast.
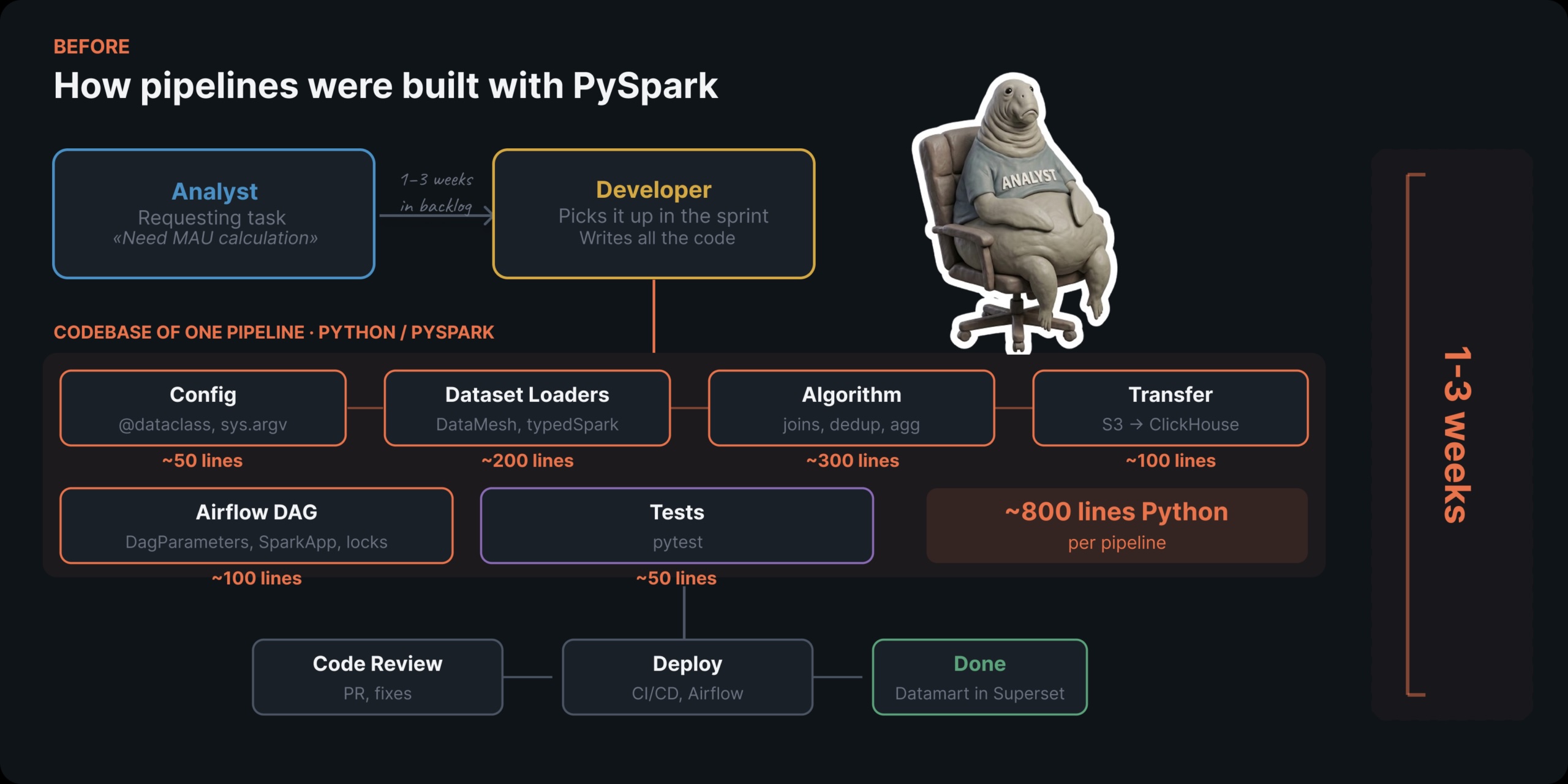
How Mindbox replaced PySpark with YAML-based pipelines using dlt, dbt, and Trino
How we replaced Python pipelines with dlt, dbt, and Trino — and cut delivery time from weeks to one day.
 towardsdatascience.com·1mo ago
towardsdatascience.com·1mo agoWhy we built an Edge benchmarking tool for Turso
We often get questions like this, and it's hard to properly convey in writing the potentially drastic latency differences between a typical
Comments
Sign in to join the conversation.
No comments yet. Be the first.